# 文章目录# 一、教学讲解视频教学讲解视频地址:视频地址
# 二、环境准备对应的 pom.xml 依赖代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 2.1.3.RELEASE</version > <relativePath /> </parent > <groupId > com.yjq.programmer</groupId > <artifactId > ShardingJDBC</artifactId > <version > 1.0-SNAPSHOT</version > <name > ShardingJDBC</name > <properties > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <maven.compiler.source > 1.8</maven.compiler.source > <maven.compiler.target > 1.8</maven.compiler.target > </properties > <dependencies > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.6</version > <scope > runtime</scope > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.apache.shardingsphere</groupId > <artifactId > sharding-jdbc-spring-boot-starter</artifactId > <version > 4.0.0-RC1</version > </dependency > <dependency > <groupId > com.alibaba</groupId > <artifactId > druid</artifactId > <version > 1.1.19</version > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 1.3.2</version > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.12</version > <scope > test</scope > </dependency > </dependencies > <build > <pluginManagement > <plugins > <plugin > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-maven-plugin</artifactId > </plugin > </plugins > </pluginManagement > </build > </project >
# 三、水平分表# 1. 概念水平分表是在 同一个 数据库内,把同一个表的数据 按一定规则 拆分到多个 表 中。t_user_1 和 t_user_2 ,如下图。
1 2 3 4 5 6 CREATE TABLE `t_user_1` ( `id ` bigint(20) NOT NULL, `name` varchar(100) DEFAULT NULL, `sex` int(2) DEFAULT NULL, PRIMARY KEY (`id `) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# 2. 代码①我们先来看下我们的 SpringBoot 的 配置文件 代码。
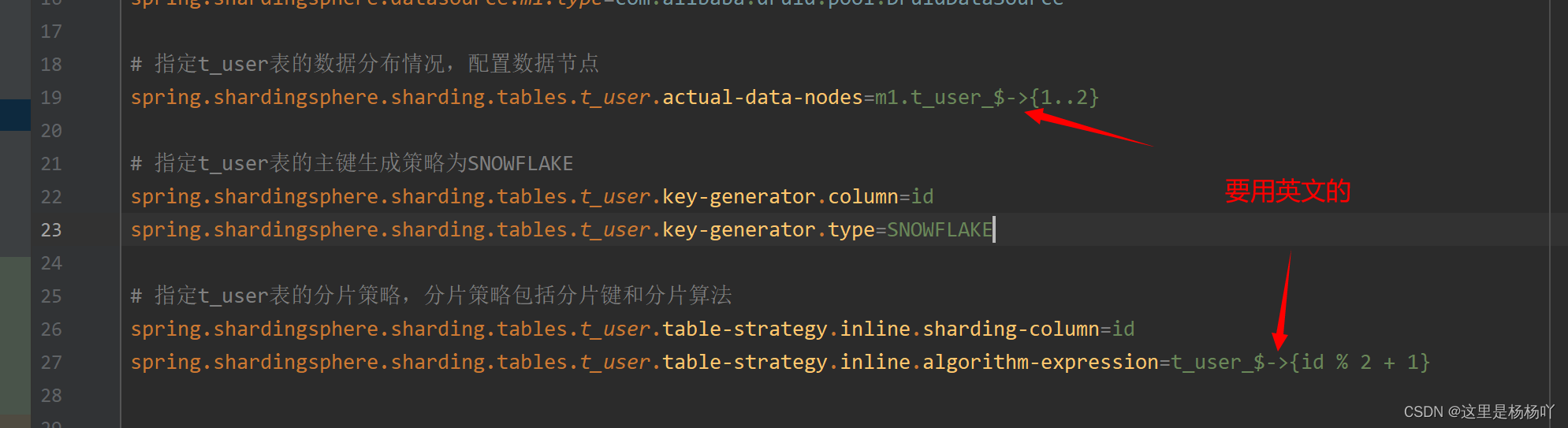
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 server.port=8081 server.servlet.session.timeout=1800 spring.jackson.time-zone=GMT+8 spring.jackson.date-format=yyyy-MM-dd HH:mm:ss spring.shardingsphere.datasource.names=m1 spring.shardingsphere.datasource.m1.url=jdbc:mysql://127.0.0.1:3306/db_user1?serverTimezone=GMT%2b8&useUnicode=true &characterEncoding=utf8 spring.shardingsphere.datasource.m1.username=root spring.shardingsphere.datasource.m1.password= spring.shardingsphere.datasource.m1.driver‐class‐name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.sharding.tables.t_user.actual‐data‐nodes=m1.t_user_$->{1..2} spring.shardingsphere.sharding.tables.t_user.key‐generator.column=id spring.shardingsphere.sharding.tables.t_user.key‐generator.type=SNOWFLAKE spring.shardingsphere.sharding.tables.t_user.table‐strategy.inline.sharding‐column=id spring.shardingsphere.sharding.tables.t_user.table‐strategy.inline.algorithm‐expression=t_user_$->{id % 2 + 1} logging.level.root=info logging.level.com.yjq.programmer.dao=debug spring.shardingsphere.props.sql.show=true mybatis.mapper-locations=classpath*:mappers/**/*.xml
首先定义数据源 m1,并对 m1 进行实际的参数配置。
指定 t_user 表的数据分布情况,他分布在 m1.t_user_1,m1.t_user_2。
指定 t_user 表的主键生成策略为 SNOWFLAKE,SNOWFLAKE 是一种分布式自增算法,保证 id 全局唯一。
定义 t_user 分表策略,id 为偶数的数据落在 t_user_1,为奇数的落在 t_user_2,所以分表策略的表达式为 t_user_$->{id% 2 + 1}。
踩坑注意! 如果启动项目有如下报错,可能是配置文件中的 -> 没有用英文类型的。
②然后接下来就写我们的 dao 层、 mapper 层和 单元测试 的代码,去测试我们的水平分表情况下 插入 和 查询 的结果。
dao 层
1 2 3 4 5 6 public interface UserDao { int insertUser(User user); List<User> selectUser(); }
mapper 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.yjq.programmer.dao.UserDao" > <insert id ="insertUser" parameterType="com.yjq.programmer.entity.User" > insert into t_user(name) values ( </insert> <select id ="selectUser" resultType="com.yjq.programmer.entity.User" > select * from t_user </select> </mapper> 12345678910111213 单元测试 @Test public void testShardingJDBCInsert User user = new User(); for (int i=0; i<10; i++) { user.setName("小明" + i); if (userDao.insertUser(user) == 1) { logger.info("插入成功!" ); } else { logger.info("插入失败!" ); } } } @Test public void testShardingJDBCSelect List<User> userList = userDao.selectUser(); logger.info("查询结果:{}" , JSONObject.toJSONString(userList)); }
③结果说明插入 查询 sharding-jdbc 分别去不同的表检索数据,达到预期目标;如果有传入 id 进行查询,sharding-jdbc 也会根据 t_user 的分表策略去不同的表检索数据 。
# 四、水平分库# 1. 概念水平分库是把同一个表的数据按 一定规则 拆分到不同的 数据库 中,每个库可以放在不同的服务器上。水平分表 的基础上多加了一个 db_user2 的数据库。
# 2. 代码①我们先来看下我们的 SpringBoot 的 配置文件 代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 server.port=8081 server.servlet.session.timeout=1800 spring.jackson.time-zone=GMT+8 spring.jackson.date-format=yyyy-MM-dd HH:mm:ss spring.shardingsphere.datasource.names=m1,m2 spring.shardingsphere.datasource.m1.url=jdbc:mysql://127.0.0.1:3306/db_user1?serverTimezone=GMT%2b8&useUnicode=true &characterEncoding=utf8 spring.shardingsphere.datasource.m1.username=root spring.shardingsphere.datasource.m1.password= spring.shardingsphere.datasource.m1.driver‐class‐name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m2.url=jdbc:mysql://127.0.0.1:3306/db_user2?serverTimezone=GMT%2b8&useUnicode=true &characterEncoding=utf8 spring.shardingsphere.datasource.m2.username=root spring.shardingsphere.datasource.m2.password= spring.shardingsphere.datasource.m2.driver‐class‐name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.sharding.tables.t_user.database‐strategy.inline.sharding‐column=sex spring.shardingsphere.sharding.tables.t_user.database‐strategy.inline.algorithm‐expression=m$->{sex % 2 + 1} spring.shardingsphere.sharding.tables.t_user.actual‐data‐nodes=m$->{1..2}.t_user_$->{1..2} spring.shardingsphere.sharding.tables.t_user.key‐generator.column=id spring.shardingsphere.sharding.tables.t_user.key‐generator.type=SNOWFLAKE spring.shardingsphere.sharding.tables.t_user.table‐strategy.inline.sharding‐column=id spring.shardingsphere.sharding.tables.t_user.table‐strategy.inline.algorithm‐expression=t_user_$->{id % 2 + 1} logging.level.root=info logging.level.com.yjq.programmer.dao=debug spring.shardingsphere.props.sql.show=true mybatis.mapper-locations=classpath*:mappers/**/*.xml
配置了两个数据源,分配指向两个不同的数据库 db_user1 和 db_user2。
配置分库策略,sex 字段为偶数的数据落在 m1 数据源,为奇数的落在 m2 数据源,所以分库策略的表达式为 m$->{sex % 2 + 1}。
配置分表策略,分表策略和上面水平分表保持一致。
也就是当有数据来时,先根据 sex 字段判断落入哪个数据源,然后再根据 id 字段来判断落入哪个表中。
②然后接下来就写我们的 dao 层、 mapper 层和 单元测试 的代码,去测试我们的水平分表情况下 插入 和 查询 的结果。
dao 层
1 2 3 4 5 6 public interface UserDao { int insertUser(User user); List<User> selectUser(User user); }
mapper 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.yjq.programmer.dao.UserDao" > <insert id ="insertUser" parameterType="com.yjq.programmer.entity.User" > insert into t_user(name, sex) values ( </insert> <select id ="selectUser" parameterType="com.yjq.programmer.entity.User" resultType="com.yjq.programmer.entity.User" > select * from t_user t where t.sex = </select> </mapper> 12345678910111213 单元测试 @Test public void testShardingJDBCInsert User user = new User(); for (int i=0; i<10; i++) { user.setName("小明" + i); user.setSex(1); if (userDao.insertUser(user) == 1) { logger.info("插入成功!" ); } else { logger.info("插入失败!" ); } } } @Test public void testShardingJDBCSelect User user = new User(); user.setSex(1); user.setId(821357967667363840L); List<User> userList = userDao.selectUser(user); logger.info("查询结果:{}" , JSONObject.toJSONString(userList)); }
③结果说明插入 查询 如果有传入 sex 进行查询,sharding-jdbc 会根据 t_user 的分库策略去锁定查哪个库,如果有传入 id 进行查询,sharding-jdbc 会根据 t_user 的分表策略去锁定查哪个表 。
# 五、垂直分表# 1. 概念垂直分表一般就是把表的结构进行改造,关于如何改造,可以浏览我的另一篇博客:分库分表:垂直分库、垂直分表、水平分库、水平分表四个概念 大致的思路就是:将一个表按照字段分成多表,每个表存储其中一部分字段。
# 2. 代码无代码,垂直分表属于表结构设计层面。
# 六、垂直分库# 1. 概念垂直分库就是在 垂直分表 把表进行分类后,放到 不同的数据库 中。每个库可以放在不同的服务器上,它的核心理念是 专库专用 。关于如何改造,同样可以浏览我的另一篇博客:分库分表:垂直分库、垂直分表、水平分库、水平分表四个概念
# 2. 代码无代码,垂直分库属于数据库设计层面。
# 七、公共表# 1. 概念公共表属于系统中数据量较小,变动少,而且属于高频联合查询的依赖表。参数表、数据字典表等属于此类型。 可以将这类表在每个数据库都保存一份 ,所有更新操作都同时发送到所有分库执行。
# 2. 代码①只需要在 SpringBoot 的 配置文件 中加入下面这行来指明公共表就行。如果有多个公共表,用逗号拼接就行
1 2 3 spring.shardingsphere.sharding.broadcast‐tables=t_dict 12
②然后接下来就写我们的 dao 层、 mapper 层和 单元测试 的代码,去测试我们的公共表的 插入 的结果。dao 层
1 2 3 4 public interface DictDao { int insertDict(Dict dict); }
mapper 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.yjq.programmer.dao.DictDao" > <insert id ="insertDict" parameterType="com.yjq.programmer.entity.Dict" > insert into t_dict(id , name) values ( </insert> </mapper> 单元测试 @Test public void testShardingJDBCInsertDict Dict dict = new Dict(); dict.setId(1); dict.setName("字典名称" ); if (dictDao.insertDict(dict) == 1) { logger.info("插入成功!" ); } else { logger.info("插入失败!" ); } }
③结果说明插入 每个库中的对应的公共表 中都能看到,达到预期目标。
# 关于我Brath 是一个热爱技术的 Java 程序猿,公众号「InterviewCoder」定期分享有趣有料的精品原创文章!
非常感谢各位人才能看到这里,原创不易,文章如果有帮助可以关注、点赞、分享或评论,这都是对我的莫大支持!