ElasticSearch 处理检索海量数据“神器”?

海量数据我们是如何去检索数据呢,如何快速定位呢,去查询后台数据库吗?还是走缓存,是什么缓存能承载这么大的符合呢,并且快速检索出来?对于海量的数据是对系统极大的压力,我们该从什么角度去处理这个棘手的问题呢?
# ElasticSearch 处理检索海量数据 “神器”?

# 1.1 介绍
Elasticsearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful
web 接口。Elasticsearch 是用 Java 语言开发的,并作为 Apache 许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch 用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在 Java、.NET(C#)、PHP、Python、Apache
Groovy、Ruby 和许多其他语言中都是可用的。根据 DB-Engines 的排名显示,Elasticsearch 是最受欢迎的企业搜索引擎,其次是 Apache
Solr,也是基于 Lucene。
# 1.2 es 介绍 “官网地址们”
- 官方文档
- 中文官方文档 3. 中文社区
# 2.1 基本介绍
1、Index(索引) 动词,相当于 MySQL 中的 insert; 名词,相当于 MySQL 中的 Database
2、Type(类型) 在 Index(索引)中,可以定义一个或多个类型。 类似于 MySQL 中的 Table;每一种类型的数据放在一起;
3、Document(文档)
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格
式的,Document 就像是 MySQL 中的某个 Table 里面的内容;
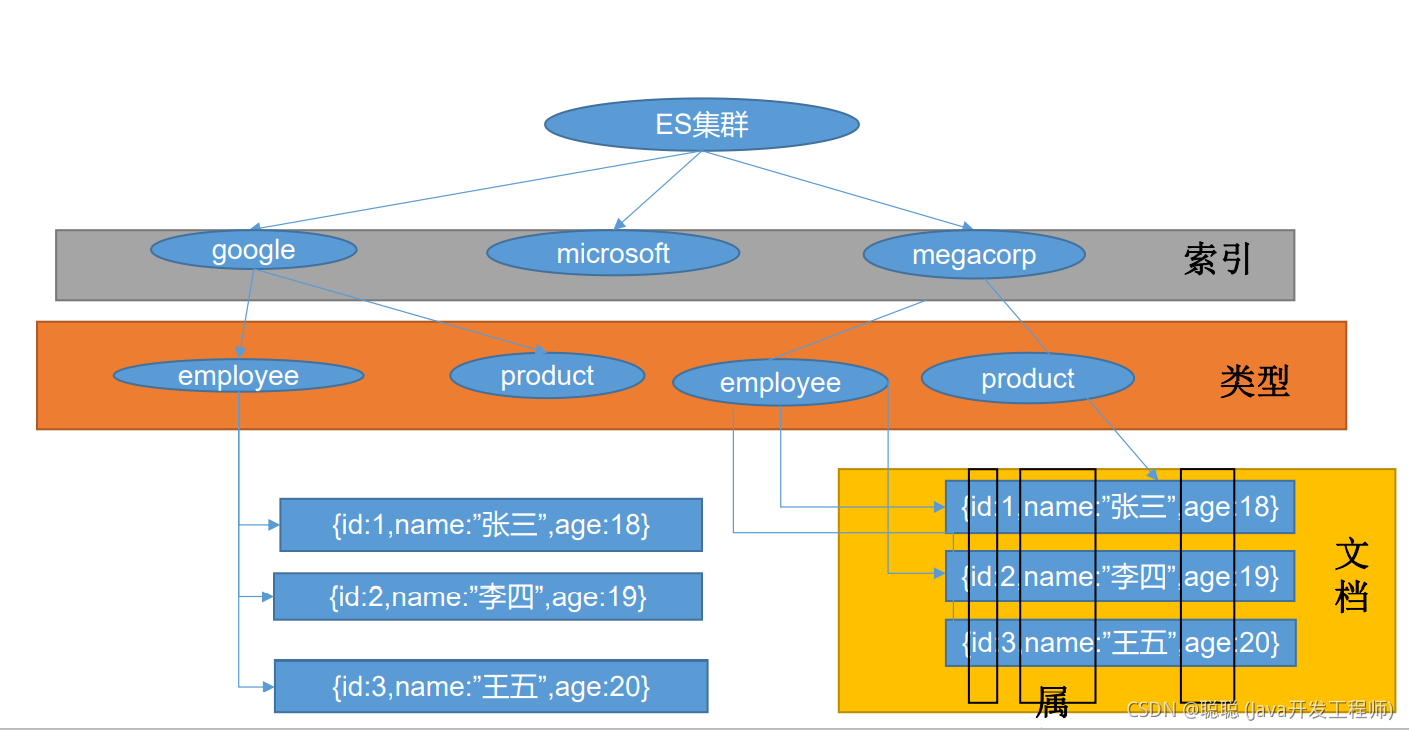
# 2.2 ES 是如何进行检索的呢
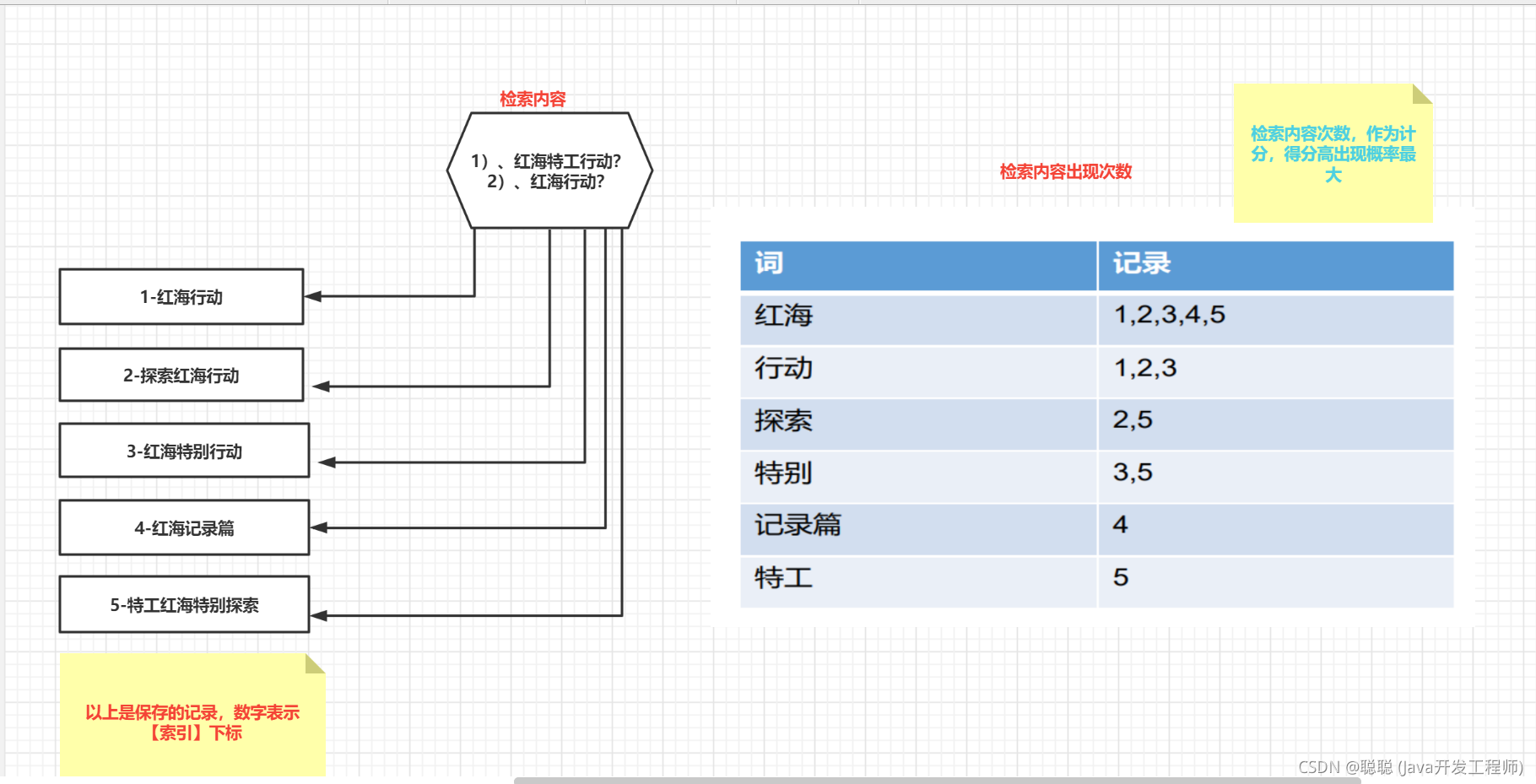
# 2.3 ElasticSearch 长啥样呢,有无操作界面
ElasticSearch
是有操作界面的,它需要配置 Kibana,和它一起操作方便,也是主流的一种搭配方式,安装这两个工具,不做过多介绍Kibana 介绍 Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现
# 2.4 初步检索
1 | 1、_cat |
# 2.4.1 在 postMan 测试数据
1 | PUT customer/external/1 |
2.4.2、查询文档
1 | GET customer/external/1 |
2.4.3、更新文档
1 | POST customer/external/1/_update |
2.4.4、删除文档 & 索引
1 | DELETE customer/external/1 |
2.4.5 bulk 批量 API
1 | POST customer/external/_bulk |
# 2.4 SearchAPI
1 | ES 支持两种基本方式检索 : |
其他在 Kibana 操作的语句,都可以在 es 官网去查询,不做过多的赘述!!!
# 2.5、Mapping 映射

Mapping(映射) Mapping 是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和
索引的。比如,使用 mapping 来定义: ? 哪些字符串属性应该被看做全文本属性(full text fields)。 ?
哪些属性包含数字,日期或者地理位置。 ? 文档中的所有属性是否都能被索引(_all 配置)。 ? 日期的格式。 ?
自定义映射规则来执行动态添加属性。
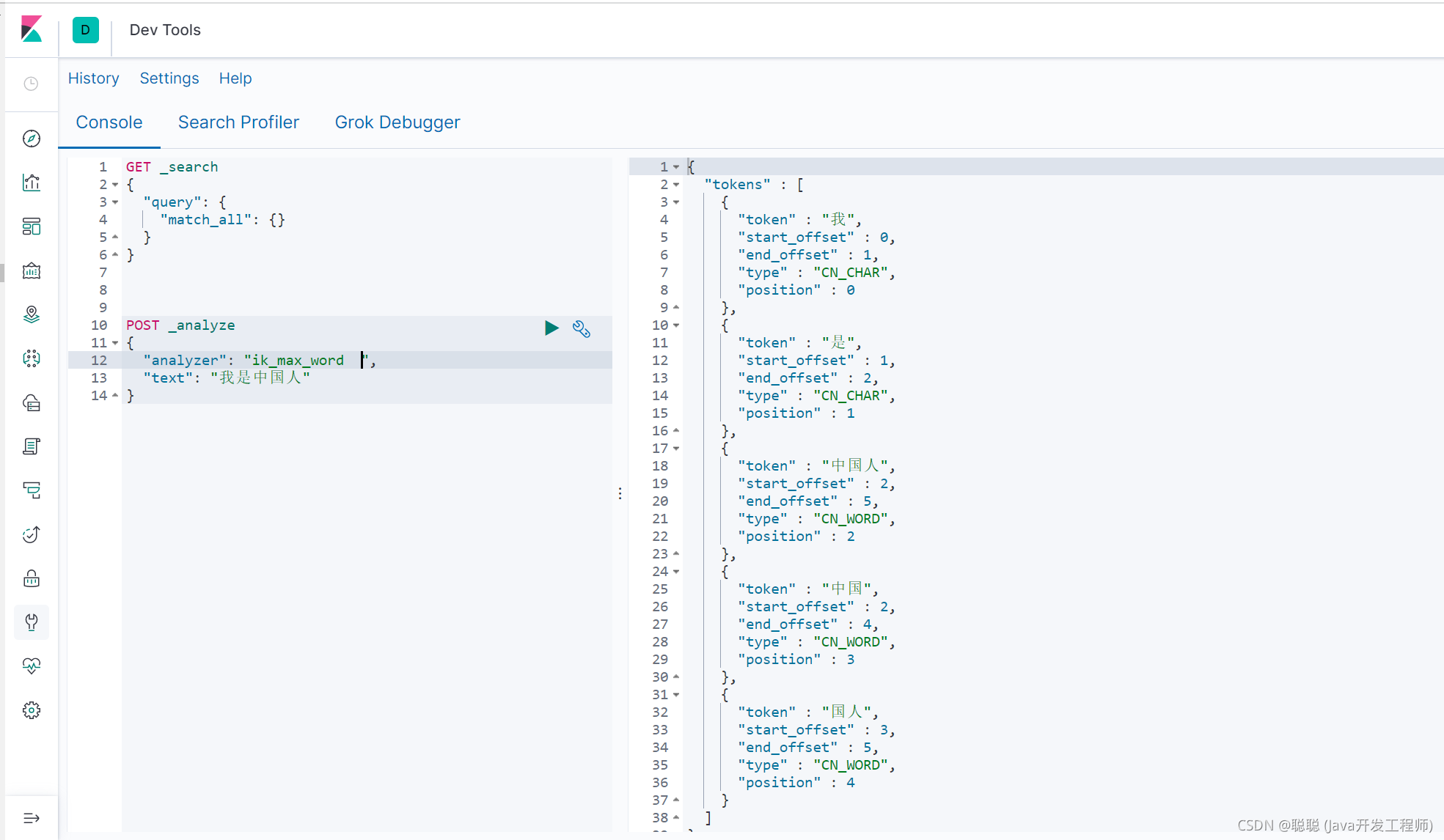
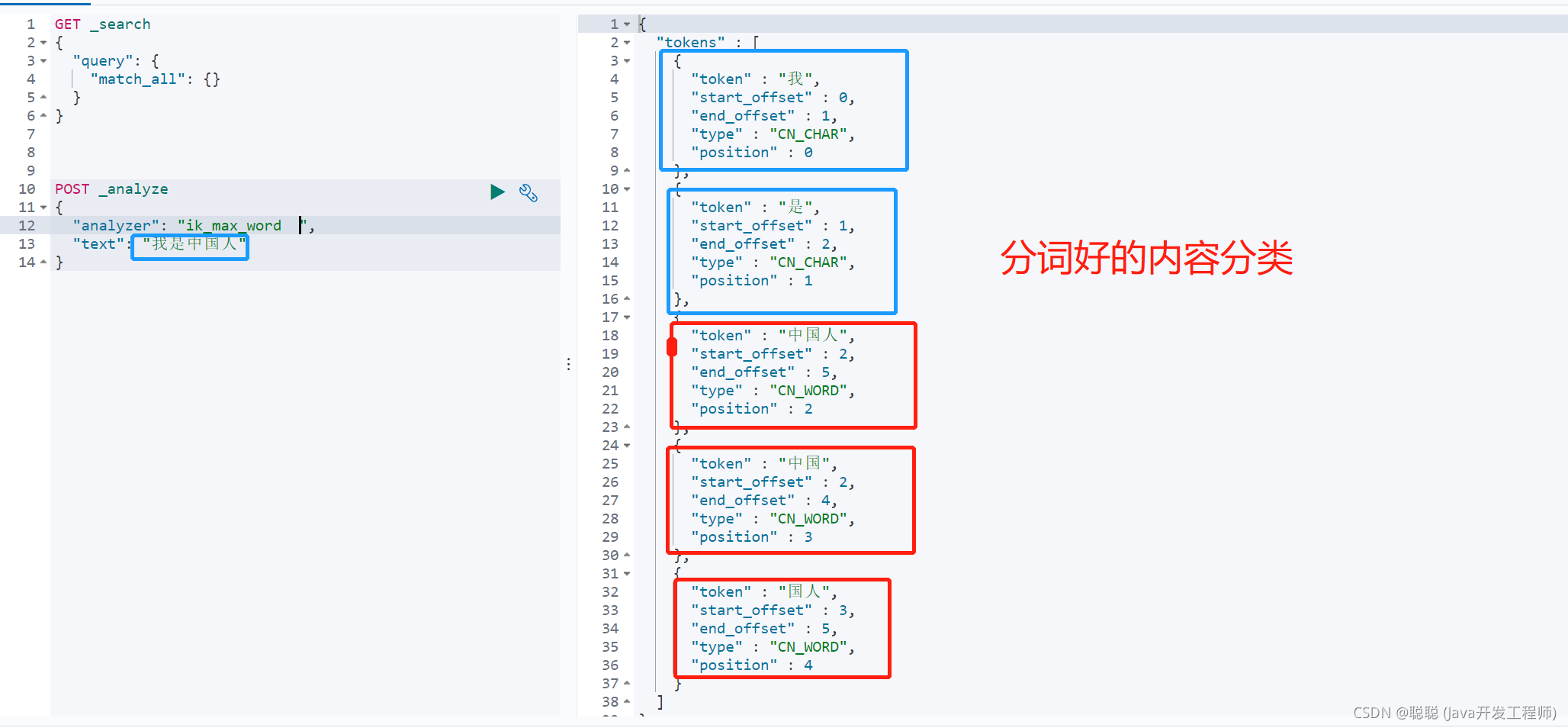
# 2.6 分词
个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立 的单词),然后输出 tokens 流。
例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割 为
[Quick, brown, fox!]。 该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position
位置(用于 phrase 短 语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的
start (起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。
Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
2.6.1 安装分词器
注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装
https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2
对应 es 版本安装
# 总结
elasticsearch
功能是非常强大的,可以作为生成环境的 ELK 日志存储,方便检索,也可以部署集群,提高效率,最主要是它是走内存的,查询效率极高,为大数据检索而生!!!
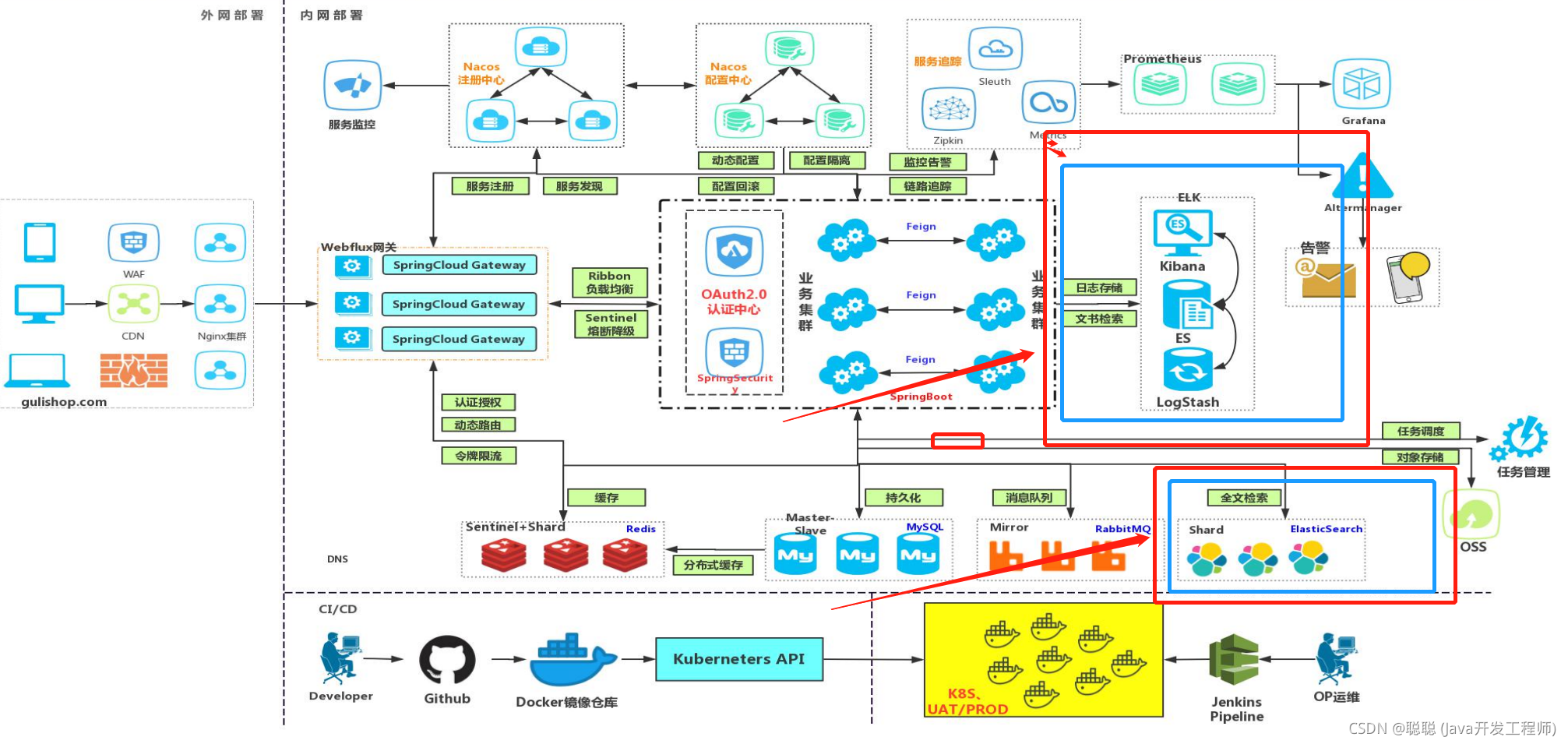
# 使用场景(Es)
# 关于我
Brath 是一个热爱技术的 Java 程序猿,公众号「InterviewCoder」定期分享有趣有料的精品原创文章!

非常感谢各位人才能看到这里,原创不易,文章如果有帮助可以关注、点赞、分享或评论,这都是对我的莫大支持!

