# Elasticsearch
# 目标
了解 ES 中的基本概念
掌握 RESTFul 操作 ES 的 CRUD
掌握 Spring Data Elasticsearch 操作 ES
# 简介Elasticsearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用 JSON 通过 HTTP 来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多用户,我们希望建立一个云的解决方案。因此我们利用 Elasticsearch 来解决所有这些问题及可能出现的更多其它问题。
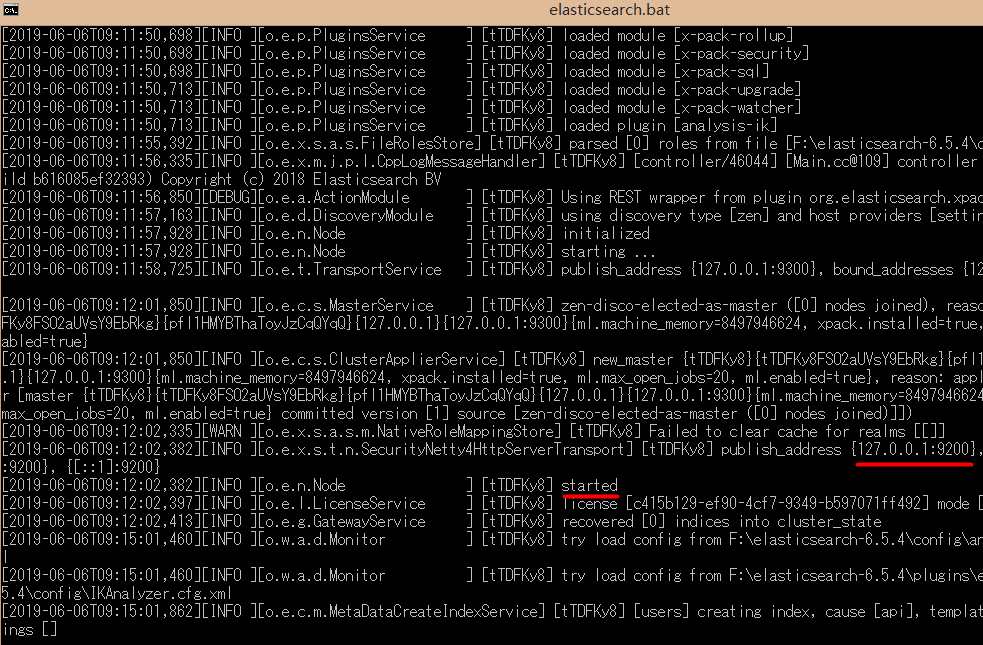
# 安装和运行该软件是基于 Java 编写的解压即用的软件,只需要有 Java 的运行环境即可,把压缩包解压后,进入到 bin 目录运行 elasticsearch.bat,出现以下界面,表示成功启动服务器
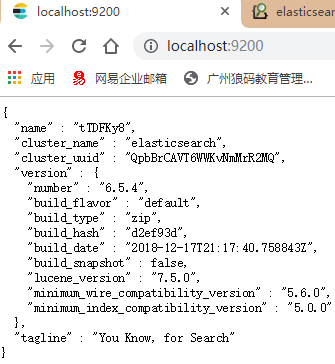
浏览器输入:localhost:9200 ,看到浏览器输出服务器的信息,表示安装成功,可以使用了
注意:程序启动后有两个端口 9200 和 9300,9200 端口用于 HTTP 协议,基于 RESTFul 来使用,9300 端口用于 TCP 协议,基于 jar 包来使用
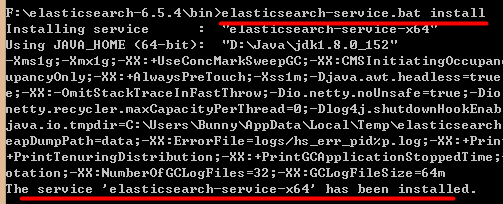
# 后台启动使用安装目录 /bin/elasticsearch-service.bat 程序可以把 Elasticsearch 安装后服务列表中,以后我们可以在服务列表来启动该程序,也可以设置成开机启动模式
注意:设置后台启动需要手动配置 Java 虚拟机的路径,使用命令 elasticsearch-service.bat manager 来配置
# 安装 head 插件Elasticsearch 默认的客户端工具是命令行形式的,操作起来不方便,也不直观看到数据的展示,所以我们需要去安装一个可视化插件,但是这些插件都是基于 H5 开发的,在谷歌的应用商店中找到 elasticsearch-head 插件,然后安装,使用该插件能比较直观的展示服务器中的数据
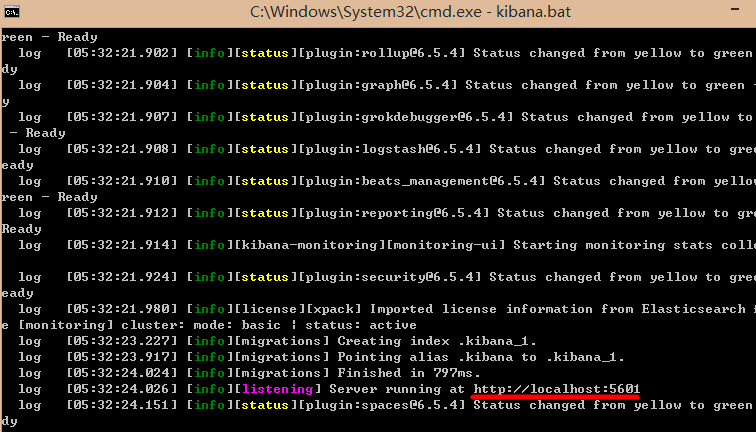
# 安装 kibana该软件也是解压即用的工具,用于管理和监控 Elasticsearch 的运作,同时内部包含了客户端工具,支持 RESTFul 操作 Elasticsearch。解压后运行 bin/kibana.bat,看到启动成功的端口号即可以使用浏览器来使用了
浏览器输入:http://localhost:5601
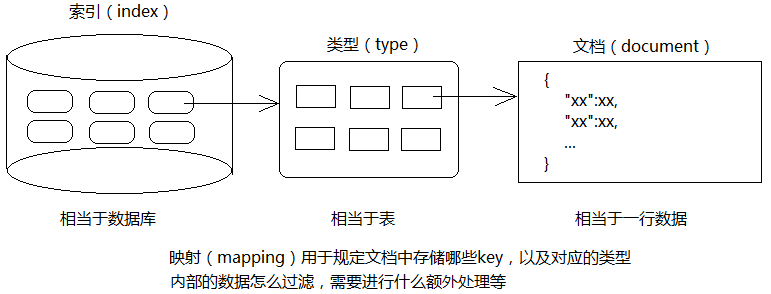
# 概念名词# 数据存储图
注意:从 Elasticsearch6 开始一个索引里面只能有一个类型,后续计划删除类型这个概念,从 ES6 开始一般让索引名称和类型名称一致
# 主要组件
索引
ES 将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于 SQL 中的一个数据库,或者一个数据存储方案 (schema)。索引由其名称 (必须为全小写字符) 进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个 ES 集群中可以按需创建任意数目的索引。
类型
类型是索引内部的逻辑分区 (category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型 (type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于表。
映射
Mapping, 就是对索引库中索引的字段名称及其数据类型进行定义,类似于 mysql 中的表结构信息。不过 es 的 mapping 比数据库灵活很多,它可以动态识别字段。一般不需要指定 mapping 都可以,因为 es 会自动根据数据格式识别它的类型,如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加 mapping。
需要注意的是映射是不可修改的,一旦确定就不允许改动,在使用自动识别功能时,会以第一个存入的文档为参考来建立映射,后面存入的文档也必须符合该映射才能存入
文档
文档是 Lucene 索引和搜索的原子单位,它是包含了一个或多个域的容器,基于 JSON 格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为多值域。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
# 分片和副本ES 的分片 (shard) 机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的 Lucene 索引完成索引数据的分割存储功能,这每一个物理的 Lucene 索引称为一个分片 (shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为 5 个。
Shard 有两种类型:primary 和 replica,即主 shard 及副本 shard。Primary shard 用于文档存储,每个新的索引会自动创建 5 个 Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其 Primary shard 的数量将不可更改。Replica shard 是 Primary Shard 的副本,用于冗余数据及提高搜索性能。每个 Primary shard 默认配置了一个 Replica shard,但也可以配置多个,且其数量可动态更改。ES 会根据需要自动增加或减少这些 Replica shard 的数量。
# 分词器把文本内容按照标准进行切分,默认的是 standard,该分词器按照单词切分,内容转变为小写,去掉标点,遇到每个中文字符都当成 1 个单词处理,后面会安装开源的中文分词器插件(ik)
# 感受分词器效果1 2 3 4 5 6 7 8 9 10 11 12 13 14 先创建一个名叫shop_product的索引,然后再感受分词效果 PUT /shop_product 默认分词器: GET /shop_product/_analyze { "text":"I am Groot" } GET /shop_product/_analyze { "text":"英特尔酷睿i7处理器" } 结论:默认的分词器只能对英文正常分词,不能对中文正常分词
# 安装 IK 分词器直接把压缩文件中的内容解压,然后放在 elasticsearch/plugins 下,然后重启即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 IK分词器: ik_smart:粗力度分词 ik_max_word:细力度分词 GET /shop_product/_analyze { "text":"I am Groot", "analyzer":"ik_smart" } GET /shop_product/_analyze { "text":"英特尔酷睿i7处理器", "analyzer":"ik_smart" } GET /shop_product/_analyze { "text":"英特尔酷睿i7处理器", "analyzer":"ik_max_word" } 结论:都能正常分词
# 拓展词库最简单的方式就是找到 IK 插件中的 config/main.dic 文件,往里面添加新的词汇,然后重启服务器即可
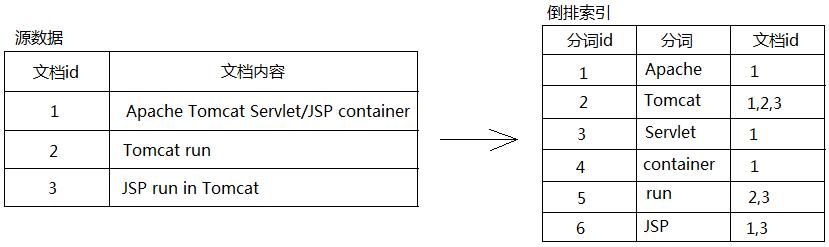
# 倒排索引
# 基本操作(了解)# 索引操作建表索引,相当于在是在建立数据库
# 建立索引1 2 3 4 5 6 7 8 9 语法:PUT /索引名 在没有特殊设置的情况下,默认有5个分片,1个备份,也可以通过请求参数的方式来指定 参数格式: { "settings": { "number_of_shards": 5, //设置5个片区 "number_of_replicas": 1 //设置1个备份 } }
# 删除索引# 映射操作# 建立索引和映射1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 语法:PUT /索引名 { "mappings": { 类型名: { "properties..0": { 字段名: { "type": 字段类型, "analyzer": 分词器类型, "search_analyzer": 分词器类型, ... }, ... } } } } 字段类型:double / long / integer / text / keyword / date / binary 注意:text和keyword都是字符串类型,但是只有text类型的数据才能分词,字段的配置一旦确定就不能更改 映射的配置项有很多,我们可以根据需要只配置用得上的属性
# 查询映射# CRUD 操作# 文档操作# 新增和替换文档1 2 3 4 5 6 7 8 9 10 11 12 13 语法:PUT /索引名/类型名/文档ID { field1: value1, field2: value2, ... } 注意:当索引/类型/映射不存在时,会使用默认设置自动添加 ES中的数据一般是从别的数据库导入的,所以文档的ID会沿用原数据库中的ID 索引库中没有该ID对应的文档时则新增,拥有该ID对应的文档时则替换 需求1:新增一个文档 需求2:替换一个文档
每一个文档都内置以下字段
_index:所属索引
_type:所属类型
_id:文档 ID
_version:乐观锁版本号
_source:数据内容
# 查询文档1 2 3 4 5 6 语法: 根据ID查询 -> GET /索引名/类型名/文档ID 查询所有(基本查询语句) -> GET /索引名/类型名/_search 需求1:根据文档ID查询一个文档 需求2:查询所有的文档
查询所有结果中包含以下字段
took:耗时
_shards.total:分片总数
hits.total:查询到的数量
hits.max_score:最大匹配度
hits.hits:查询到的结果
hits.hits._score:匹配度
# 删除文档1 2 3 4 5 语法:DELETE /索引名/类型名/文档ID 注意:这里的删除并且不是真正意义上的删除,仅仅是清空文档内容而已,并且标记该文档的状态为删除 需求1:根据文档ID删除一个文档 需求2:替换刚刚删除的文档
# 高级查询数据准备:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 PUT /shop_product { "mappings": { "shop_product": { "properties": { "id": { "type": "integer" }, "title":{ "type": "text", "analyzer": "ik_smart", "search_analyzer": "ik_smart" }, "price":{ "type": "double" }, "intro":{ "type": "text", "analyzer": "ik_smart", "search_analyzer": "ik_smart" }, "brand":{ "type": "keyword" } } } } } POST /shop_product/shop_product/_bulk {"create":{"_id": 1}} {"id":1,"title":"Apple iPhone XR (A2108) 128GB 白色 移动联通电信4G手机 双卡双待","price":5299,"intro":"【iPhoneXR限时特惠!】6.1英寸视网膜显示屏,A12仿生芯片,面容识别,无线充电,支持双卡!选【换修无忧版】获 AppleCare 原厂服务,享只换不修!更有快速换机、保值换新、轻松月付!","brand":"Apple"} {"create":{"_id": 2}} {"id":2,"title":"Apple 2019款 Macbook Pro 13.3【带触控栏】八代i7 18G 256G RP645显卡 深空灰 苹果笔记本电脑 轻薄本 MUHN2CH/A","price":15299,"intro":"【八月精选】Pro2019年新品上市送三重好礼,现在购买领满8000减400元优惠神劵,劵后更优惠!","brand":"Apple"} {"create":{"_id": 3}} {"id":3,"title":"Apple iPad Air 3 2019年新款平板电脑 10.5英寸(64G WLAN版/A12芯片/Retina显示屏/MUUL2CH/A)金色","price":3788,"intro":"8月尊享好礼!买iPad即送蓝牙耳机!领券立减!多款产品支持手写笔!【新一代iPad,总有一款适合你】选【换修无忧版】获 AppleCare 原厂服务,享只换不修!更有快速换机、保值换新、轻松月付!","brand":"Apple"} {"create":{"_id": 4}} {"id":4,"title":"华为HUAWEI MateBook X Pro 2019款 英特尔酷睿i5 13.9英寸全面屏轻薄笔记本电脑(i5 8G 512G 3K 触控) 灰","price":7999,"intro":"3K全面屏开启无界视野;轻薄设计灵动有型,HuaweiShare一碰传","brand":"华为"} {"create":{"_id": 5}} {"id":5,"title":"华为 HUAWEI Mate20 X (5G) 7nm工艺5G旗舰芯片全面屏超大广角徕卡三摄8GB+256GB翡冷翠5G双模全网通手机","price":6199,"intro":"【5G双模,支持SA/NSA网络,7.2英寸全景巨屏,石墨烯液冷散热】5G先驱,极速体验。","brand":"华为"} {"create":{"_id": 6}} {"id":6,"title":"华为平板 M6 10.8英寸麒麟980影音娱乐平板电脑4GB+64GB WiFi(香槟金)","price":2299,"intro":"【华为暑期购】8月2日-4日,M5青春版指定爆款型号优惠100元,AI语音控制","brand":"华为"} {"create":{"_id": 7}} {"id":7,"title":"荣耀20 PRO DXOMARK全球第二高分 4800万四摄 双光学防抖 麒麟980 全网通4G 8GB+128GB 蓝水翡翠 拍照手机","price":3199,"intro":"白条6期免息!麒麟980,4800万全焦段AI四摄!荣耀20系列2699起,4800万超广角AI四摄!","brand":"荣耀"} {"create":{"_id": 8}} {"id":8,"title":"荣耀MagicBook Pro 16.1英寸全面屏轻薄性能笔记本电脑(酷睿i7 8G 512G MX250 IPS FHD 指纹解锁)冰河银","price":6199,"intro":"16.1英寸无界全面屏金属轻薄本,100%sRGB色域,全高清IPS防眩光护眼屏,14小时长续航,指纹一健开机登录,魔法一碰传高速传输。","brand":"荣耀"} {"create":{"_id": 9}} {"id":9,"title":"荣耀平板5 麒麟8核芯片 GT游戏加速 4G+128G 10.1英寸全高清屏影音平板电脑 WiFi版 冰川蓝","price":1549,"intro":"【爆款平板推荐】哈曼卡顿专业调音,10.1英寸全高清大屏,双喇叭立体环绕音,配置多重护眼,值得拥有!","brand":"荣耀"} {"create":{"_id": 10}} {"id":10,"title":"小米9 4800万超广角三摄 6GB+128GB全息幻彩蓝 骁龙855 全网通4G 双卡双待 水滴全面屏拍照智能游戏手机","price":2799,"intro":"限时优惠200,成交价2799!索尼4800万广角微距三摄,屏下指纹解锁!","brand":"小米"} {"create":{"_id": 11}} {"id":11,"title":"小米(MI)Pro 2019款 15.6英寸金属轻薄笔记本(第八代英特尔酷睿i7-8550U 16G 512GSSD MX250 2G独显) 深空灰","price":6899,"intro":"【PCIE固态硬盘、72%NTSC高色域全高清屏】B面康宁玻璃覆盖、16G双通道大内存、第八代酷睿I7处理器、专业级调校MX150","brand":"小米"} {"create":{"_id": 12}} {"id":12,"title":"联想(Lenovo)拯救者Y7000P 2019英特尔酷睿i7 15.6英寸游戏笔记本电脑(i7 9750H 16G 1T SSD GTX1660Ti 144Hz)","price":9299,"intro":"超大1T固态,升级双通道16G内存一步到位,GTX1660Ti电竞级独显,英特尔9代i7H高性能处理器,144Hz电竞屏窄边框!","brand":"联想"}
Elasticsearch 基于 JSON 提供完整的查询 DSL(Domain Specific Language:领域特定语言)来定义查询。
1 2 基本语法: GET /索引名/类型名/_search
一般都是需要配合查询参数来使用的,配合不同的参数有不同的查询效果
参数配置项可以参考博客:https://www.jianshu.com/p/6333940621ec
# 结果排序1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 参数格式: { "sort": [ {field: 排序规则}, ... ] } 排序 GET /shop_product/shop_product/_search { "sort": [ { "price": { "order": "desc" } } ] } 排序规则: asc表示升序 desc:表示降序 没有配置排序的情况下,默认按照评分降序排列
# 分页查询1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 参数格式: { "from": start, "size": pageSize } 分页 从第几个开始 每页几个 GET /shop_product/shop_product/_search { "from": 2, "size": 4, "sort": [ { "price": { "order": "desc" } } ] } 需求1:查询所有文档按照价格降序排列 需求2:分页查询文档按照价格降序排列,显示第2页,每页显示3个
# 检索查询1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 参数格式: { "query": { 检索方式: {field: value} } } 检索查询 全文检索 需求1:查询商品标题中符合"游戏 手机"的字样的商品 GET /shop_product/shop_product/_search { "query": { "match": { "title": "游戏 手机" } } } 检索查询 精准匹配 需求2:查询商品价格等于15299的商品 GET /shop_product/shop_product/_search { "query": { "term": { "price": 15299 } } } 检索查询 范围检索 需求3:查询商品价格在5000~10000之间商品,按照价格升序排列 GET /shop_product/shop_product/_search { "query": { "range": { "price": { "gte": 5000, "lte": 10000 } } }, "sort": [ { "price": { "order": "asc" } } ] } 检索方式: term表示精确匹配,value值不会被分词器拆分,按照倒排索引匹配 match表示全文检索,value值会被分词器拆分,然后去倒排索引中匹配 range表示范围检索,其value值是一个对象,如{ "range": {field: {比较规则: value, ...}} } 比较规则有gt / gte / lt / lte 等 注意:term和match都能用在数值和字符上,range用在数值上 需求1:查询商品标题中符合"游戏 手机"的字样的商品 需求2:查询商品价格等于15299的商品 需求3:查询商品价格在5000~10000之间商品,按照价格升序排列
# 关键字查询1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 参数格式: { "query": { "multi_match": { "query": value, "fields": [field1, field2, ...] } } } 关键字查询 需求1:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品 GET /shop_product/shop_product/_search { "query": { "multi_match": { "query": "蓝牙 指纹 双卡", "fields": ["title", "intro"] } } } multi_match:表示在多个字段间做检索,只要其中一个字段满足条件就能查询出来,多用在字段上 需求1:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品
# 高亮显示1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 参数格式: { "query": { ... }, "highlight": { "fields": { field1: {}, field2: {}, ... }, "pre_tags": 开始标签, "post_tags" 结束标签 } } 高亮显示 需求1:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品,并且高亮显示 GET /shop_product/shop_product/_search { "query": { "multi_match": { "query": "蓝牙 指纹 双卡", "fields": ["title", "intro"] } }, "highlight": { "fields": { "title": {}, "intro": {} }, "pre_tags":"<h1>", "post_tags":"</h1>" } } highlight:表示高亮显示,需要在fields中配置哪些字段中检索到该内容需要高亮显示 必须配合检索(term / match)一起使用 需求1:查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品,并且高亮显示
# 逻辑查询1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 参数格式: { "query": { "bool": { 逻辑规则: [ {检索方式: {field: value}}, ... ], ... } } } 逻辑查询 需求1:查询商品标题中符合"i7"的字样并且价格大于7000的商品 GET /shop_product/shop_product/_search { "query": { "bool": { "must": [ {"match": { "title": "i7" }}, {"range": { "price": { "gt": 7000 } }} ] } } } 逻辑查询 需求2:查询商品标题中符合"pro"的字样或者价格在1000~3000的商品 GET /shop_product/shop_product/_search { "query": { "bool": { "should": [ {"match": { "title": "pro" }}, {"range": { "price": { "gte": 1000, "lte": 3000 } }} ] } } } 逻辑规则:must / should / must_not,相当于and / or / not 需求1:查询商品标题中符合"i7"的字样并且价格大于7000的商品 需求2:查询商品标题中符合"pro"的字样或者价格在1000~3000的商品
# 过滤查询1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 参数格式: { "query": { "bool": { "filter": [ { 检索方式: { field: value } }, ... ] } } } 过滤查询 不评分 GET /shop_product/shop_product/_search { "query": { "bool": { "filter": [ {"match": { "title": "pro" }} ] } } } 从效果上讲过滤查询和检索查询能做一样的效果 区别在于过滤查询不评分,结果能缓存,检索查询要评分,结果不缓存 一般是不会直接使用过滤查询,都是在检索了一定数据的基础上再使用
关于 filter 的更多认知推荐大家读这篇博客:https://blog.csdn.net/laoyang360/article/details/80468757
# 分组查询1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 参数格式: { "size": 0, "aggs": { 自定义分组字段: { "terms": { "field": 分组字段, "order": {自定义统计字段:排序规则}, "size": 10 //默认显示10组 }, "aggs": { //分组后的统计查询,相当于MySQL分组函数查询 自定义统计字段: { 分组运算: { "field": 统计字段 } } } } } } 分组查询 需求1:按照品牌分组,统计各品牌的数量 GET /shop_product/shop_product/_search { "size": 0, "aggs": { "brand_group": { "terms": { "field": "brand", "order": {"brand_group":"desc"}, "size": 10 }, "aggs": { "brand_group": { "value_count": { "field": "id" } } } } } } 分组查询 需求2:按照品牌分组,统计各品牌的平均价格 GET /shop_product/shop_product/_search { "size": 0, "aggs": { "brand_group": { "terms": { "field": "brand", "order": {"brand_group":"desc"}, "size": 10 }, "aggs": { "brand_group": { "avg": { "field": "price" } } } } } } 分组查询 需求3:按照品牌分组,统计各品牌的价格数据 GET /shop_product/shop_product/_search { "size": 0, "aggs": { "brand_group_aggs": { "terms": { "field": "brand", "order": {"brand_group_aggs.count":"desc"}, "size": 10 }, "aggs": { "brand_group_aggs": { "stats": { "field": "price" } } } } } } 分组运算:avg / sum / min / max / value_count / stats(执行以上所有功能的) 注意:这里是size=0其目的是为了不要显示hit内容,专注点放在观察分组上 需求1:按照品牌分组,统计各品牌的数量 需求2:按照品牌分组,统计各品牌的平均价格 需求3:按照品牌分组,统计各品牌的价格数据
# 批处理(了解)当需要集中的批量处理文档时,如果依然使用传统的操作单个 API 的方式,将会浪费大量网络资源,Elasticsearch 为了提高操作的性能,专门提供了批处理的 API
# mget 批量查询1 2 3 4 5 6 7 8 语法: GET /索引名/类型/_mget { "docs": [ {"_id": 文档ID}, ... ] }
# bulk 批量增删改1 2 3 4 5 6 7 8 9 10 11 语法: POST /索引名/类型/_bulk {动作:{"_id": 文档ID}} {...} {动作:{"_id": 文档ID}} {...} 动作:create / update / delete,其中delete只有1行JSON,其他操作都是有2行JSON,并且JSON不能格式化,如果是update动作,它的数据需要加个key为doc 如: {"update": {"_id": xx}} {"doc": {"xx":xx, "xx":xx}}
# Spring Data Elasticsearch# 准备环境# 导入依赖1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.3.RELEASE</version> </parent> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!--SpringBoot整合Spring Data Elasticsearch的依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.8.3</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build>
# 编写 DOMAIN1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 /** @Document:配置操作哪个索引下的哪个类型 @Id:标记文档ID字段 @Field:配置映射信息,如:分词器 */ @Getter@Setter@ToString @NoArgsConstructor @AllArgsConstructor @Document(indexName="shop_product", type="shop_product") public class Product { @Id private String id; @Field(analyzer="ik_max_word",searchAnalyzer="ik_max_word", type=FieldType.Text) private String title; private Integer price; @Field(analyzer="ik_max_word",searchAnalyzer="ik_max_word", type=FieldType.Text) private String intro; @Field(type=FieldType.Keyword) private String brand; }
# 配置连接信息1 2 3 4 5 #application.properties # 配置集群名称,名称写错会连不上服务器,默认elasticsearch spring.data.elasticsearch.cluster-name=elasticsearch # 配置集群节点 spring.data.elasticsearch.cluster-nodes=localhost:9300
# ElasticsearchRepository该接口是框架封装的用于操作 Elastsearch 的高级接口,只要我们自己的写个接口去继承该接口就能直接对 Elasticsearch 进行 CRUD 操作
1 2 3 4 5 6 7 8 9 /** 泛型1:domain的类型 泛型2:文档主键类型 该接口直接该给Spring,底层会使用JDK代理的方式创建对象,交给容器管理 */ @Repository public interface ProductESRepository extends ElasticsearchRepository<Product, String> { // 符合Spring Data规范的高级查询方法 }
# 完成 CRUD + 分页 + 排序# 组件介绍1 2 3 4 5 6 7 8 9 10 11 ElasticsearchRepository:框架封装的用于便捷完成常用操作的工具接口 ElasticsearchTemplate:框架封装的用于便捷操作Elasticsearch的模板类 NativeSearchQueryBuilder:用于生成查询条件的构建器,需要去封装各种查询条件 QueryBuilder:该接口表示一个查询条件,其对象可以通过QueryBuilders工具类中的方法快速生成各种条件 boolQuery():生成bool条件,相当于 "bool": { } matchQuery():生成match条件,相当于 "match": { } rangeQuery():生成range条件,相当于 "range": { } AbstractAggregationBuilder:用于生成分组查询的构建器,其对象通过AggregationBuilders工具类生成 Pageable:表示分页参数,对象通过PageRequest.of(页数, 容量)获取 SortBuilder:排序构建器,对象通过SortBuilders.fieldSort(字段).order(规则)获取
# ElasticsearchTemplate该模板类,封装了便捷操作 Elasticsearch 的模板方法,包括 索引 / 映射 / CRUD 等底层操作和高级操作,该对象用起来会略微复杂些,尤其是对于查询,还需要把查询到的结果自己封装对象
1 2 3 //该对象已经由SpringBoot完成自动配置,直接注入即可 @Autowired private ElasticsearchTemplate template;
一般情况下,ElasticsearchTemplate 和 ElasticsearchRepository 是分工合作的,ElasticsearchRepository 已经能完成绝大部分的功能,如果遇到复杂的查询则要使用 ElasticsearchTemplate,如多字段分组、高亮显示等
# 实例代码1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 @Autowired private ElasticsearchTemplate template; @Autowired private ProductESRepository repository; // 新增或者覆盖一个文档 @Test public void testSaveOrUpdate() throws Exception { // 索引库中不存在则新增,存在则覆盖 Product p = new Product("13", "华为手环 B5(Android 运动手环)", 999, "高清彩屏 腕上蓝牙耳机 心率检测 来电消息提醒", "华为"); repostitory.save(p); } // 删除一个文档 @Test public void testDelete() throws Exception { repostitory.deleteById("13"); } // 根据ID查询一个文档 @Test public void testGet() throws Exception { Optional<Product> optional = repostitory.findById("1"); optional.ifPresent(System.out::println); } // 查询所有文档 @Test public void testList() throws Exception { Iterable<Product> iter = repostitory.findAll(); iter.forEach(System.out::println); } // 分页查询文档按照价格降序排列,显示第2页,每页显示3个 @Test public void testQuery1() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); // 设置分页信息 builder.withPageable(PageRequest.of(1, 3)); // 设置排序信息 builder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC)); Page<Product> page = repostitory.search(builder.build()); System.out.println(page.getTotalElements()); //总记录数 System.out.println(page.getTotalPages()); //总页数 page.forEach(System.out::println); } // 查询商品标题中符合"游戏 手机"的字样的商品 @Test public void testQuery2() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery( QueryBuilders.matchQuery("title", "游戏 手机") ); Page<Product> page = repostitory.search(builder.build()); page.forEach(System.out::println); } // 查询商品价格等于15299的商品 @Test public void testQuery3() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery( QueryBuilders.termQuery("price", 15299) ); Page<Product> page = repostitory.search(builder.build()); page.forEach(System.out::println); } // 查询商品价格在5000~9000之间商品,按照价格升序排列 @Test public void testQuery4() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery( QueryBuilders.rangeQuery("price") .gte(5000).lte(9000) ); builder.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC)); Page<Product> page = repostitory.search(builder.build()); page.forEach(System.out::println); } // 查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品 @Test public void testQuery5() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery( QueryBuilders.multiMatchQuery("蓝牙 指纹 双卡", "title", "intro") ); Page<Product> page = repostitory.search(builder.build()); page.forEach(System.out::println); } // 查询商品标题中符合"i7"的字样并且价格大于7000的商品 @Test public void testQuery6() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery( QueryBuilders.boolQuery() .must(QueryBuilders.matchQuery("title", "i7")) .must(QueryBuilders.rangeQuery("price").gt(7000)) ); Page<Product> page = repostitory.search(builder.build()); page.forEach(System.out::println); } // 查询商品标题中符合"pro"的字样或者价格在1000~3000的商品 @Test public void testQuery7() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery( QueryBuilders.boolQuery() .should(QueryBuilders.matchQuery("title", "pro")) .should(QueryBuilders.rangeQuery("price").gte(1000).lte(3000)) ); Page<Product> page = repostitory.search(builder.build()); page.forEach(System.out::println); } // 按照品牌分组,统计各品牌的数量 @Test public void testQuery8() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.addAggregation( AggregationBuilders.terms("groupByBrand").field("brand") ); AggregatedPage<Product> page = (AggregatedPage<Product>) repostitory.search(builder.build()); // 获取自定义的分组字段 StringTerms brand = (StringTerms) page.getAggregation("groupByBrand"); brand.getBuckets().forEach(bucket -> System.out.println(bucket.getDocCount())); } // 按照品牌分组,统计各品牌的平均价格 @Test public void testQuery9() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.addAggregation( AggregationBuilders.terms("groupByBrand").field("brand") .subAggregation(AggregationBuilders.avg("avgPrice").field("price")) ); AggregatedPage<Product> page = (AggregatedPage<Product>) repostitory.search(builder.build()); // 获取自定义的分组字段 StringTerms brand = (StringTerms) page.getAggregation("groupByBrand"); brand.getBuckets().forEach(bucket -> { InternalAvg avgPrice = bucket.getAggregations().get("avgPrice"); System.out.println(avgPrice.getValue()); }); } // 按照品牌分组,统计各品牌的价格数据 @Test public void testQuery10() throws Exception { NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.addAggregation( AggregationBuilders.terms("groupByBrand").field("brand") .subAggregation(AggregationBuilders.stats("statsPrice").field("price")) ); AggregatedPage<Product> page = (AggregatedPage<Product>) repostitory.search(builder.build()); // 获取自定义的分组字段 StringTerms brand = (StringTerms) page.getAggregation("groupByBrand"); brand.getBuckets().forEach(bucket -> { InternalStats statsPrice = bucket.getAggregations().get("statsPrice"); System.out.println(statsPrice.getSumAsString()); System.out.println(statsPrice.getAvgAsString()); System.out.println(statsPrice.getMaxAsString()); System.out.println(statsPrice.getMinAsString()); System.out.println(statsPrice.getCount()); System.out.println("-----------------------"); }); } // 查询商品标题或简介中符合"蓝牙 指纹 双卡"的字样的商品,并且高亮显示 @Test public void testHighlight() throws Exception { // Java与JSON互转的工具对象 ObjectMapper mapper = new ObjectMapper(); NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); // 设置查询哪个索引中的哪个类型 builder.withIndices("shop_product").withTypes("shop_product"); builder.withQuery( QueryBuilders.multiMatchQuery("蓝牙 指纹 双卡", "title", "intro") ); builder.withHighlightFields( new HighlightBuilder.Field("title") .preTags("<span style='color:red'>").postTags("</span>"), new HighlightBuilder.Field("intro") .preTags("<span style='color:red'>").postTags("</span>") ); AggregatedPage<Product> page = template.queryForPage(builder.build(), Product.class, new SearchResultMapper() { public <T> AggregatedPage<T> mapResults(SearchResponse resp, Class<T> clazz, Pageable pageable) { List<T> list = new ArrayList<>(); try { for (SearchHit hit : resp.getHits().getHits()) { // 把查询到的JSON字符串转换成Java对象 T t = mapper.readValue(hit.getSourceAsString(), clazz); for (HighlightField field : hit.getHighlightFields().values()) { // 替换需要高亮显示的字段,用到Apache的BeanUtils工具 BeanUtils.setProperty(t, field.getName(), field.getFragments()[0].string()); } list.add(t); } } catch (Exception e) { e.printStackTrace(); return null; } long total = resp.getHits().totalHits; return new AggregatedPageImpl<>(list, pageable, total); } }); page.forEach(System.out::println); }
# springboot2.3.x 以上配置
配置关系对应
pom 相同
配置
1 2 3 4 5 6 7 ## 旧版本以spring.data.elasticsearch.开头;访问地址配置不用声明访问协议,监听es的tcp端口 #spring.data.elasticsearch.cluster-nodes=localhost:9300 #spring.data.elasticsearch.cluster-name=elasticsearch ## 新版本以spring.elasticsearch.rest.开头;访问地址配置需要声明访问协议,直接监听es访问端口 spring.elasticsearch.rest.uris=http://localhost:9200 spring.elasticsearch.rest.username=elasticsearch
使用
# 关于我Brath 是一个热爱技术的 Java 程序猿,公众号「InterviewCoder」定期分享有趣有料的精品原创文章!
非常感谢各位人才能看到这里,原创不易,文章如果有帮助可以关注、点赞、分享或评论,这都是对我的莫大支持!