# CAS 机制
# 我们先看一段代码:
启动两个线程,每个线程中让静态变量 count 循环累加 100 次。

最终输出的 count 结果一定是 200 吗?因为这段代码是非线程安全的,所以最终的自增结果很可能会小于 200。我们再加上 synchronized 同步锁,再来看一下。

加了同步锁之后,count 自增的操作变成了原子性操作,所以最终输出一定是 count=200,代码实现了线程安全。虽然 synchronized 确保了线程安全,但是在某些情况下,这并不是一个最有的选择。
关键在于性能问题。
synchronized 关键字会让没有得到锁资源的线程进入 BLOCKED 状态,而后在争夺到锁资源后恢复为 RUNNABLE 状态,这个过程中涉及到操作系统用户模式和内核模式的转换,代价比较高。
尽管 JAVA 1.6 为 synchronized 做了优化,增加了从偏向锁到轻量级锁再到重量级锁的过过度,但是在最终转变为重量级锁之后,性能仍然比较低。所以面对这种情况,我们就可以使用 java 中的 “原子操作类”。
所谓原子操作类,指的是 java.util.concurrent.atomic 包下,一系列以 Atomic 开头的包装类。如 AtomicBoolean,AtomicUInteger,AtomicLong。它们分别用于 Boolean,Integer,Long 类型的原子性操作。
现在我们尝试使用 AtomicInteger 类:

使用 AtomicInteger 之后,最终的输出结果同样可以保证是 200。并且在某些情况下,代码的性能会比 synchronized 更好。
而 Atomic 操作类的底层正是用到了 “CAS 机制”。
CAS 是英文单词 Compare and Swap 的缩写,翻译过来就是比较并替换。
CAS 机制中使用了 3 个基本操作数:内存地址 V,旧的预期值 A,要修改的新值 B。
更新一个变量的时候,只有当变量的预期值 A 和内存地址 V 当中的实际值相同时,才会将内存地址 V 对应的值修改为 B。
我们看一个例子:
\1. 在内存地址 V 当中,存储着值为 10 的变量。

\2. 此时线程 1 想把变量的值增加 1. 对线程 1 来说,旧的预期值 A=10,要修改的新值 B=11.
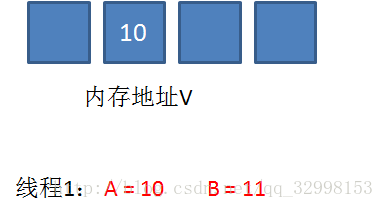
\3. 在线程 1 要提交更新之前,另一个线程 2 抢先一步,把内存地址 V 中的变量值率先更新成了 11。

\4. 线程 1 开始提交更新,首先进行 A 和地址 V 的实际值比较,发现 A 不等于 V 的实际值,提交失败。

\5. 线程 1 重新获取内存地址 V 的当前值,并重新计算想要修改的值。此时对线程 1 来说,A=11,B=12。这个重新尝试的过程被称为自旋。

\6. 这一次比较幸运,没有其他线程改变地址 V 的值。线程 1 进行比较,发现 A 和地址 V 的实际值是相等的。

\7. 线程 1 进行交换,把地址 V 的值替换为 B,也就是 12.

从思想上来说,synchronized 属于悲观锁,悲观的认为程序中的并发情况严重,所以严防死守,CAS 属于乐观锁,乐观地认为程序中的并发情况不那么严重,所以让线程不断去重试更新。
在 java 中除了上面提到的 Atomic 系列类,以及 Lock 系列类夺得底层实现,甚至在 JAVA1.6 以上版本,synchronized 转变为重量级锁之前,也会采用 CAS 机制。
CAS 的缺点:
1) CPU 开销过大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给 CPU 带来很到的压力。
2) 不能保证代码块的原子性
CAS 机制所保证的知识一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证 3 个变量共同进行原子性的更新,就不得不使用 synchronized 了。
3) ABA 问题
这是 CAS 机制最大的问题所在。(后面有介绍)
我们下面来介绍一下两个问题:
*1. JAVA 中 CAS 的底层实现 *
*2. CAS 的 ABA 问题和解决办法。*
我们看一下 AtomicInteger 当中常用的自增方法 incrementAndGet:
public final int incrementAndGet() {
for (;😉 {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
private volatile int value;
public final int get() {
return value;
}
这段代码是一个无限循环,也就是 CAS 的自旋,循环体中做了三件事:
\1. 获取当前值
\2. 当前值 + 1,计算出目标值
\3. 进行 CAS 操作,如果成功则跳出循环,如果失败则重复上述步骤
这里需要注意的重点是 get 方法,这个方法的作用是获取变量的当前值。
如何保证获取的当前值是内存中的最新值?很简单,用 volatile 关键字来保证(保证线程间的可见性)。我们接下来看一下 compareAndSet 方法的实现:

compareAndSet 方法的实现很简单,只有一行代码。这里涉及到两个重要的对象,一个是 unsafe,一个是 valueOffset。
什么是 unsafe 呢?Java 语言不像 C,C++ 那样可以直接访问底层操作系统,但是 JVM 为我们提供了一个后门,这个后门就是 unsafe。unsafe 为我们提供了硬件级别的原子操作。
至于 valueOffset 对象,是通过 unsafe.objectFiledOffset 方法得到,所代表的是 AtomicInteger 对象 value 成员变量在内存中的偏移量。我们可以简单的把 valueOffset 理解为 value 变量的内存地址。
我们上面说过,CAS 机制中使用了 3 个基本操作数:内存地址 V,旧的预期值 A,要修改的新值 B。
而 unsafe 的 compareAndSwapInt 方法的参数包括了这三个基本元素:valueOffset 参数代表了 V,expect 参数代表了 A,update 参数代表了 B。
正是 unsafe 的 compareAndSwapInt 方法保证了 Compare 和 Swap 操作之间的原子性操作。
我们现在来说什么是 ABA 问题。假设内存中有一个值为 A 的变量,存储在地址 V 中。

此时有三个线程想使用 CAS 的方式更新这个变量的值,每个线程的执行时间有略微偏差。线程 1 和线程 2 已经获取当前值,线程 3 还未获取当前值。

接下来,线程 1 先一步执行成功,把当前值成功从 A 更新为 B;同时线程 2 因为某种原因被阻塞住,没有做更新操作;线程 3 在线程 1 更新之后,获取了当前值 B。

在之后,线程 2 仍然处于阻塞状态,线程 3 继续执行,成功把当前值从 B 更新成了 A。

最后,线程 2 终于恢复了运行状态,由于阻塞之前已经获得了 “当前值 A”,并且经过 compare 检测,内存地址 V 中的实际值也是 A,所以成功把变量值 A 更新成了 B。

看起来这个例子没啥问题,但如果结合实际,就可以发现它的问题所在。
我们假设一个提款机的例子。假设有一个遵循 CAS 原理的提款机,小灰有 100 元存款,要用这个提款机来提款 50 元。

由于提款机硬件出了点问题,小灰的提款操作被同时提交了两次,开启了两个线程,两个线程都是获取当前值 100 元,要更新成 50 元。
理想情况下,应该一个线程更新成功,一个线程更新失败,小灰的存款值被扣一次。

线程 1 首先执行成功,把余额从 100 改成 50. 线程 2 因为某种原因阻塞。这时,小灰的妈妈刚好给小灰汇款 50 元。

线程 2 仍然是阻塞状态,线程 3 执行成功,把余额从 50 改成了 100。

线程 2 恢复运行,由于阻塞之前获得了 “当前值” 100,并且经过 compare 检测,此时存款实际值也是 100,所以会成功把变量值 100 更新成 50。

原本线程 2 应当提交失败,小灰的正确余额应该保持 100 元,结果由于 ABA 问题提交成功了。
怎么解决呢?加个版本号就可以了。
真正要做到严谨的 CAS 机制,我们在 compare 阶段不仅要比较期望值 A 和地址 V 中的实际值,还要比较变量的版本号是否一致。
我们仍然以刚才的例子来说明,假设地址 V 中存储着变量值 A,当前版本号是 01。线程 1 获取了当前值 A 和版本号 01,想要更新为 B,但是被阻塞了。
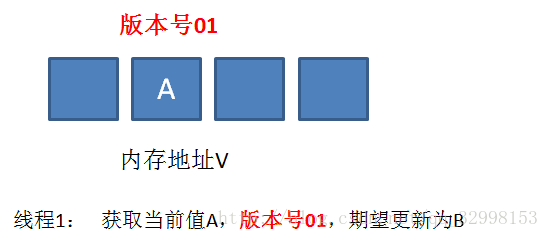
这时候,内存地址 V 中变量发生了多次改变,版本号提升为 03,但是变量值仍然是 A。
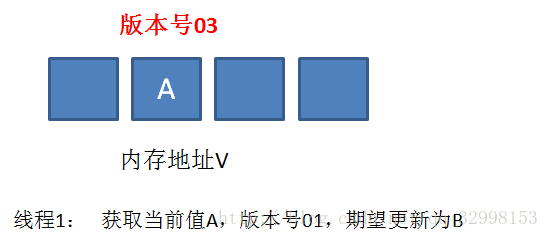
随后线程 1 恢复运行,进行 compare 操作。经过比较,线程 1 所获得的值和地址的实际值都是 A,但是版本号不相等,所以这一次更新失败。

在 Java 中,AtomicStampedReference 类就实现了用版本号作比较额 CAS 机制。
*1. java 语言 CAS 底层如何实现?*
* 利用 unsafe 提供的原子性操作方法。*
*2. 什么事 ABA 问题?怎么解决?*
* 当一个值从 A 变成 B,又更新回 A,普通 CAS 机制会误判通过检测。*
* 利用版本号比较可以有效解决 ABA 问题。*
# 关于我
Brath 是一个热爱技术的 Java 程序猿,公众号「InterviewCoder」定期分享有趣有料的精品原创文章!

非常感谢各位人才能看到这里,原创不易,文章如果有帮助可以关注、点赞、分享或评论,这都是对我的莫大支持!
 41 秒 vs 21 秒
41 秒 vs 21 秒 32 秒 vs 10 秒
32 秒 vs 10 秒