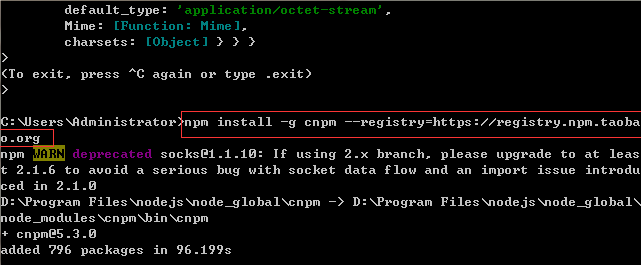
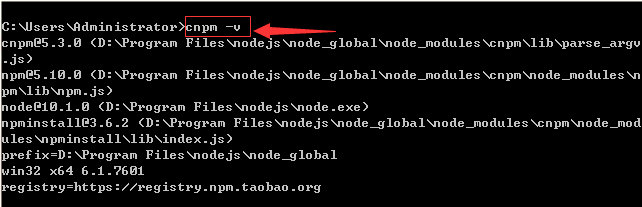
Docker 版本:Docker version 20.10.14, build a224086
测试 MySQL 版本:
MySQL5.7.37
MySQL8.0.28
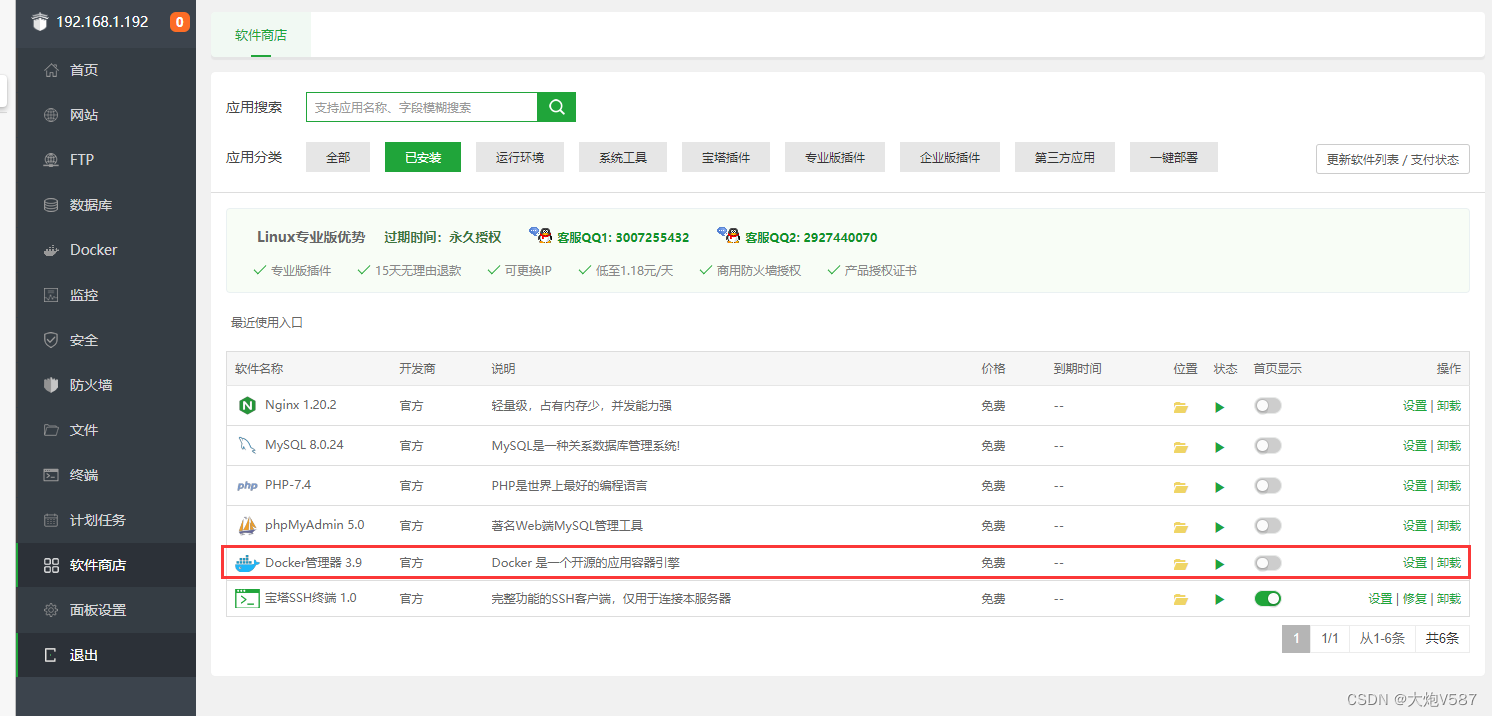
1、获取 MySQL 版本
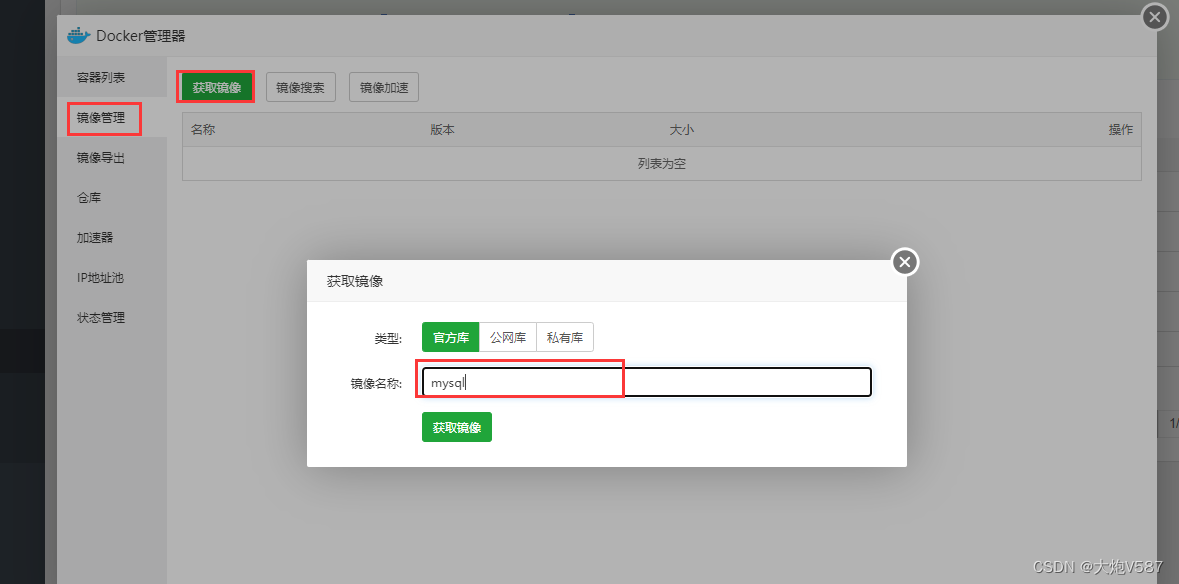
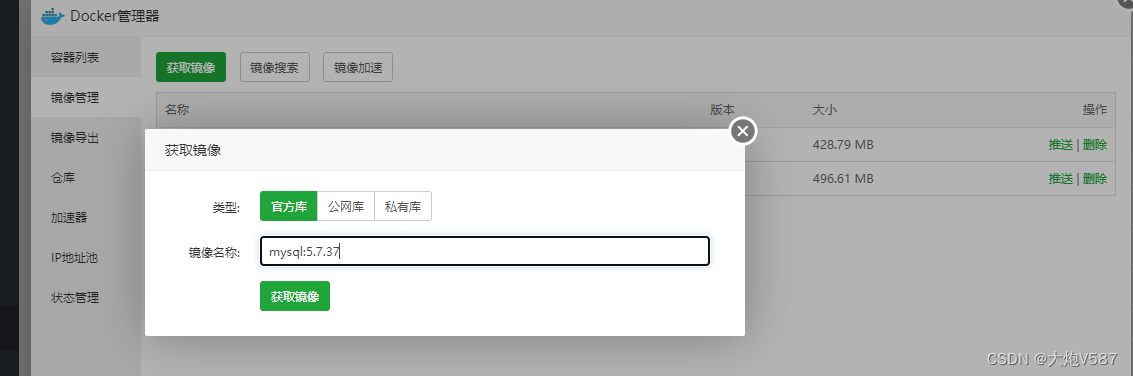
默认情况下,直接输入 mysql 名,会拉取 mysql:latest 镜像,就是最新版本的镜像,指定版本后拉取的是指定版本的 MySQL 镜像,如 mysql:5.7.37
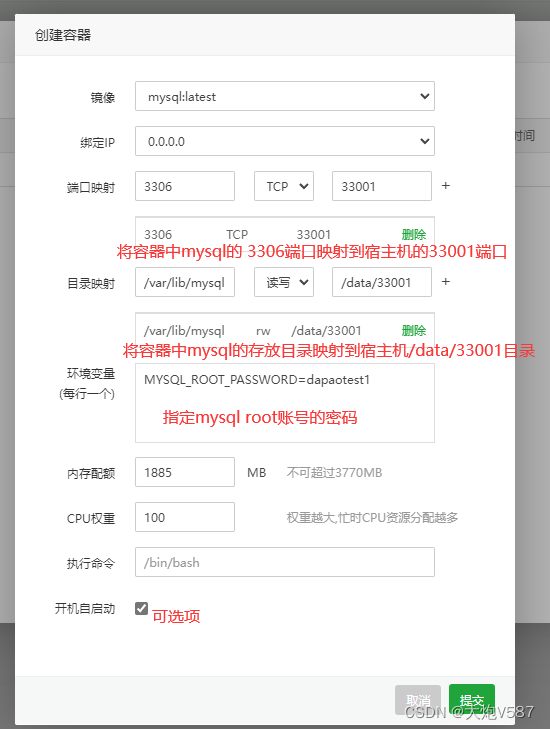
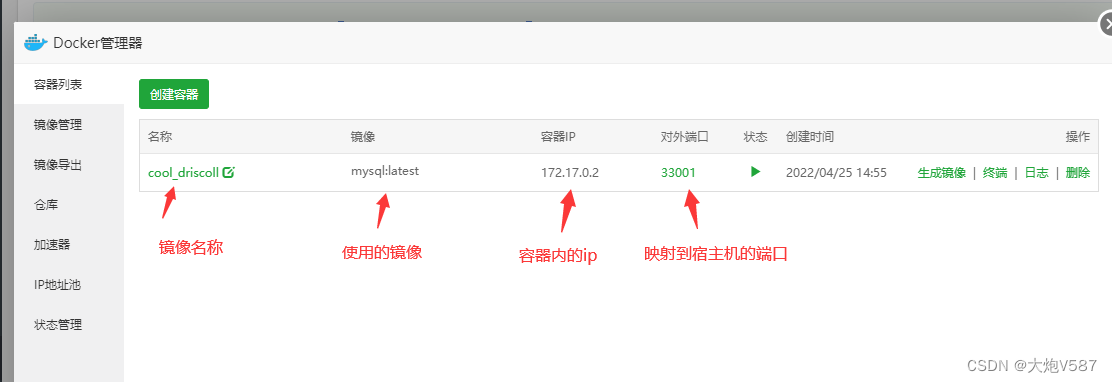
2、创建容器:
指定容器中数据库的密码:
MYSQL_ROOT_PASSWORD=dapaotest1
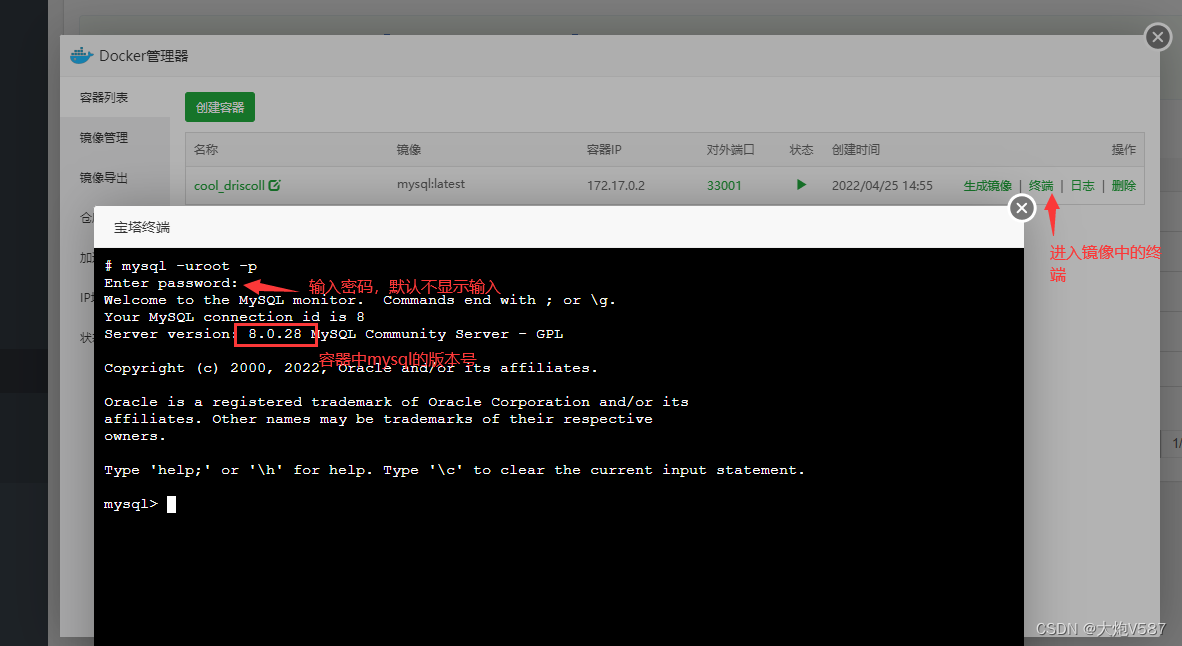
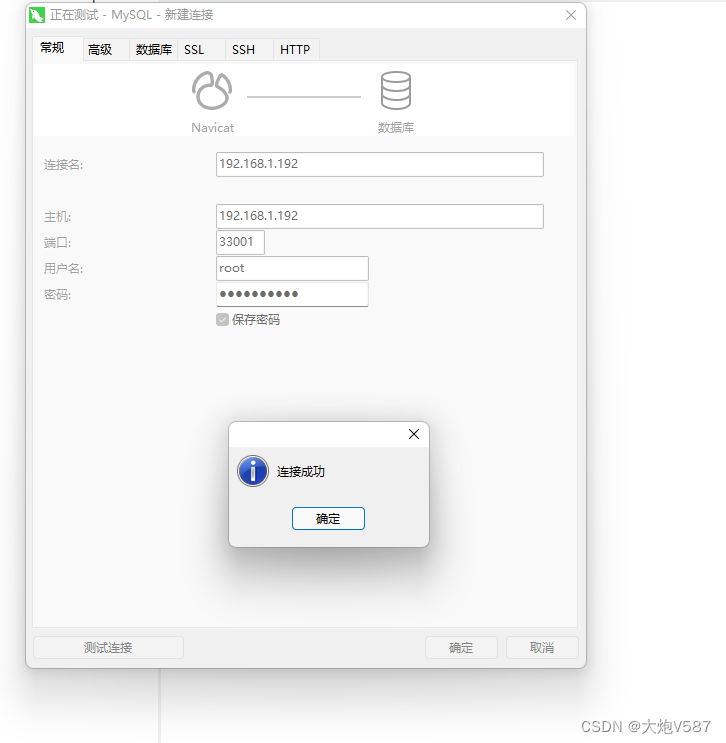
3、容器创建成功后,进入终端命令行查看数据库
4、创建数据库表
1 2 3 4 5 6 7 8 9 10 11 12
查看数据库的命令 show databases; 创建数据库的命令 create database dapaodocker; 创建用户的命令 create user 'dapaodocker'@'%' identified by 'dapao666!'; 授权 grant all on dapaodocker.* to dapaodocker@'%';
Change the applicationId in android\app\build.gradle file like this:
from :
1 2 3 4
defaultConfig { // TODO: Specify your own unique Application ID (https://developer.android.com/studio/build/application-id.html). applicationId "com.xxxxxxxxxxx.yyyyyy1" }
to :
1 2 3 4
defaultConfig { // TODO: Specify your own unique Application ID (https://developer.android.com/studio/build/application-id.html). applicationId "com.xxxxxxxxxxx.yyyyyy2" }
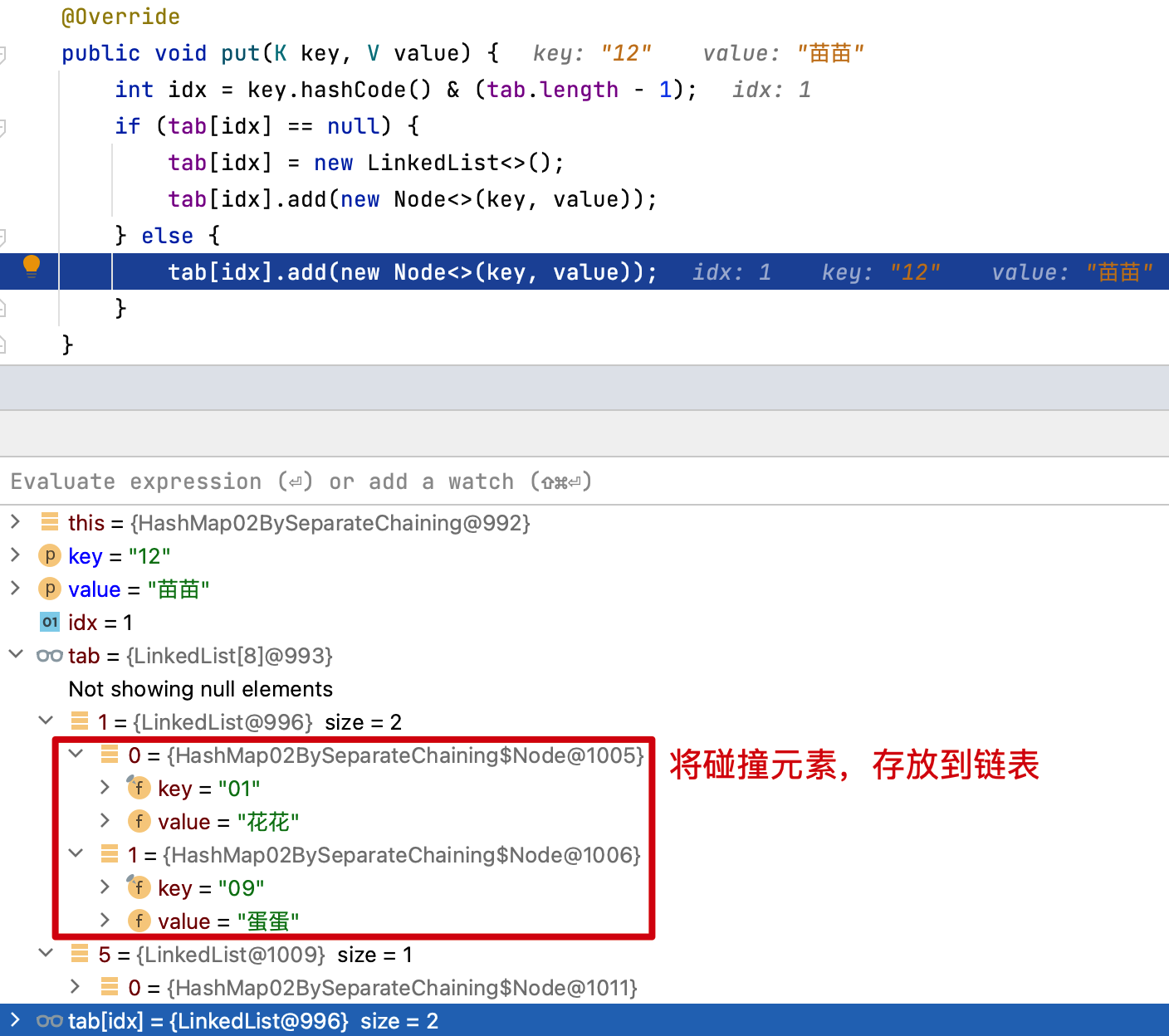
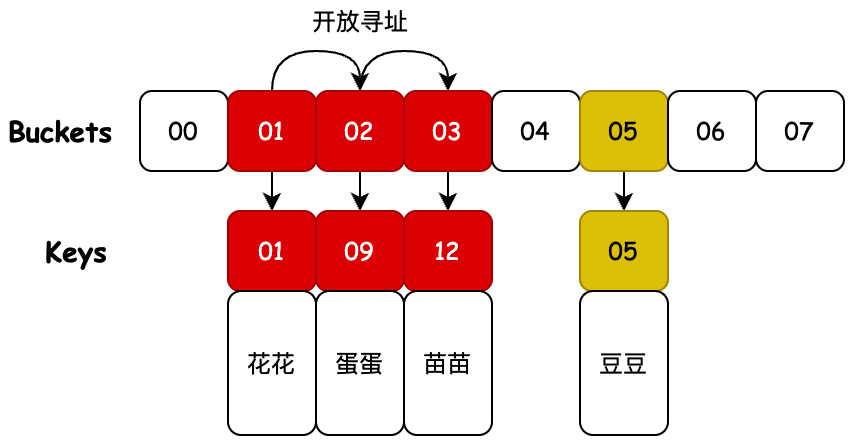
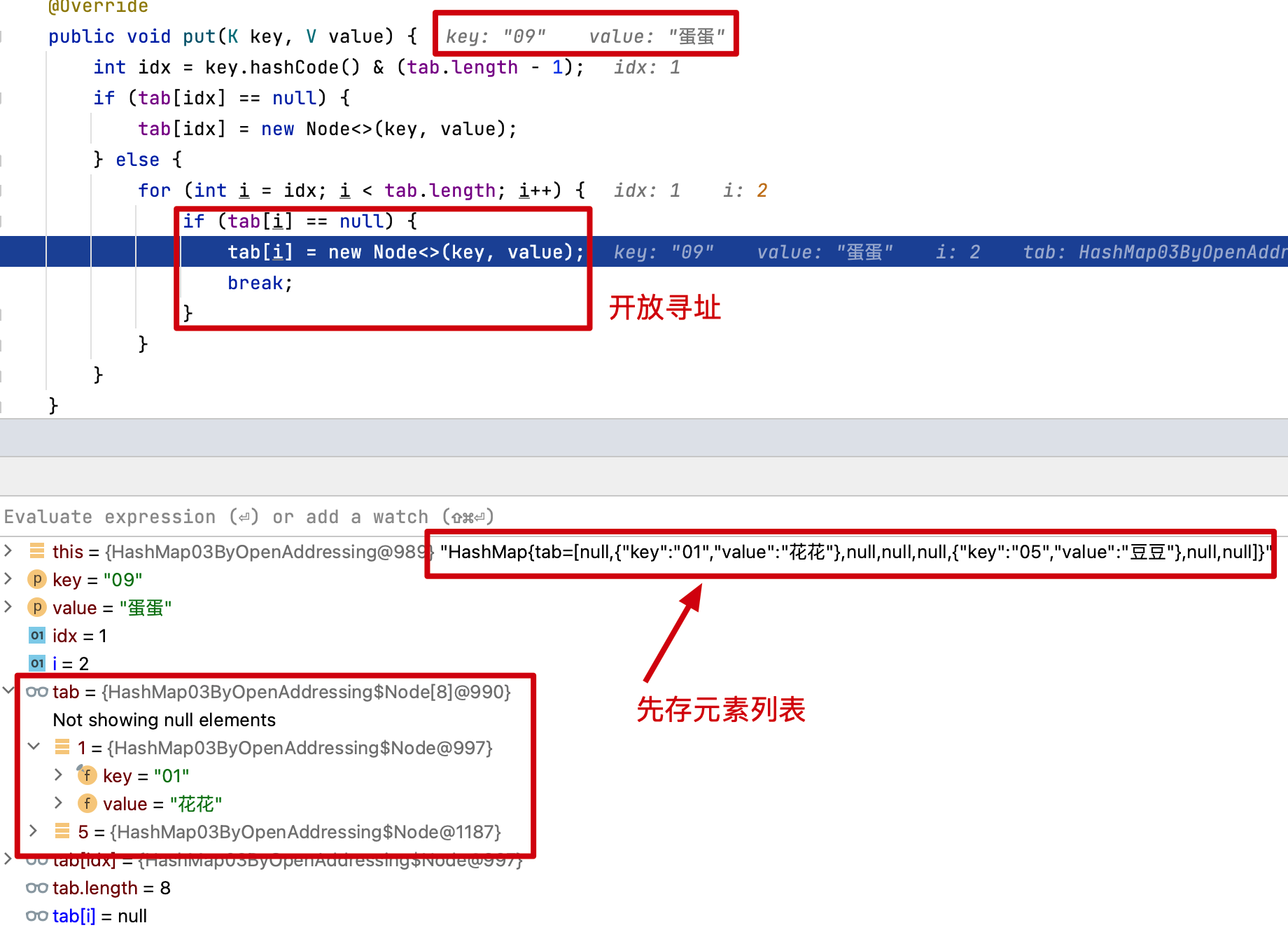
哈希散列的想法在不同的地方独立出现。1953 年 1 月,汉斯・彼得・卢恩 (Hans Peter Luhn) 编写了一份 IBM 内部备忘录,其中使用了散列和链接。开放寻址后来由 AD Linh 在 Luhn 的论文上提出。大约在同一时间,IBM Research 的 Gene Amdahl、Elaine M. McGraw、Nathaniel Rochester 和 Arthur Samuel 为 IBM 701 汇编器实现了散列。 线性探测的开放寻址归功于 Amdahl,尽管 Ershov 独立地有相同的想法。“开放寻址” 一词是由 W. Wesley Peterson 在他的文章中创造的,该文章讨论了大文件中的搜索问题。
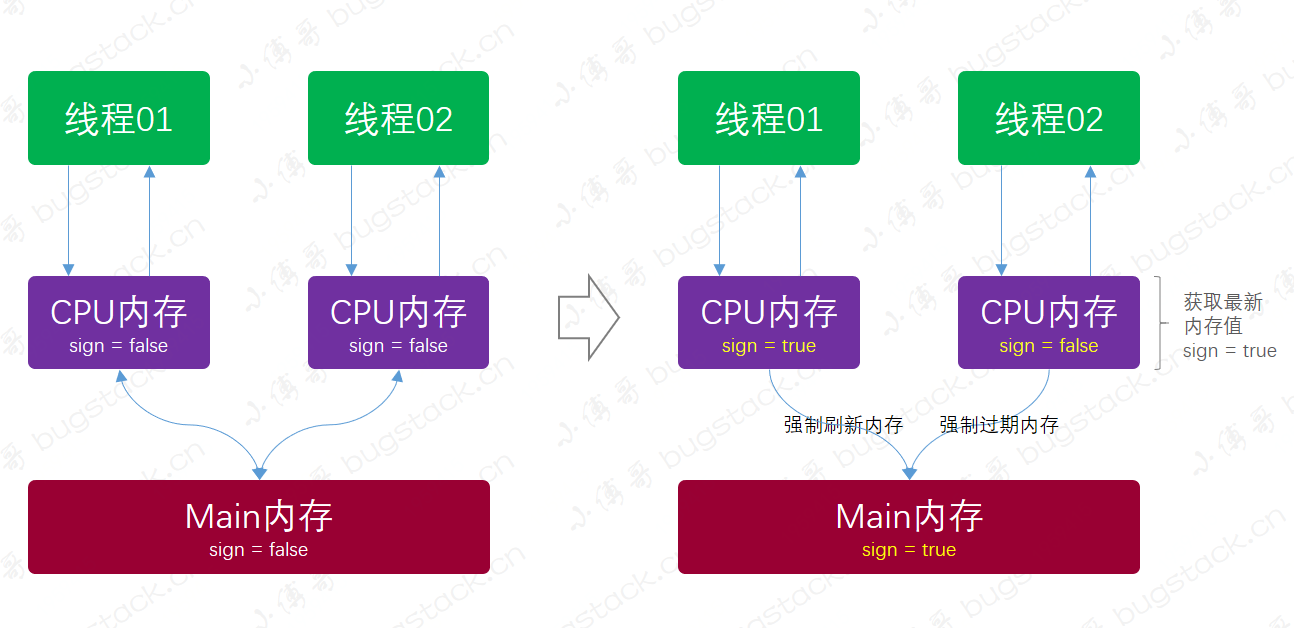
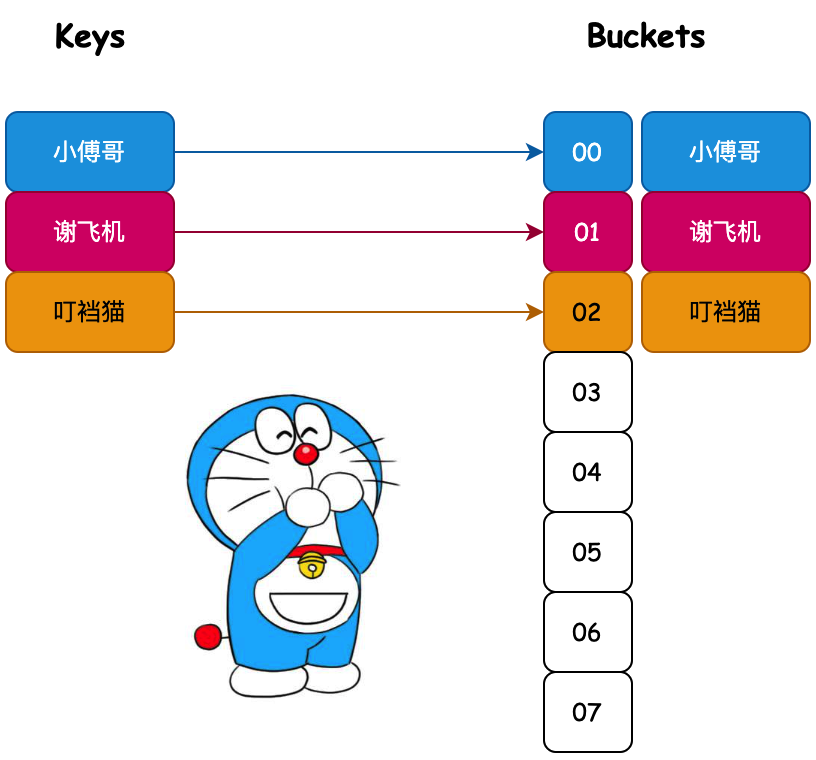
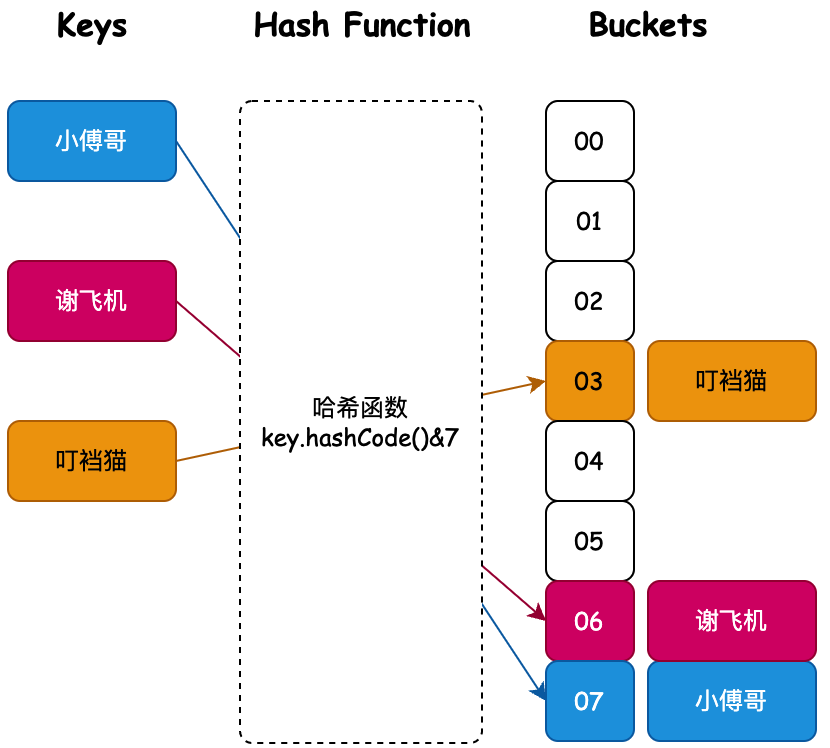
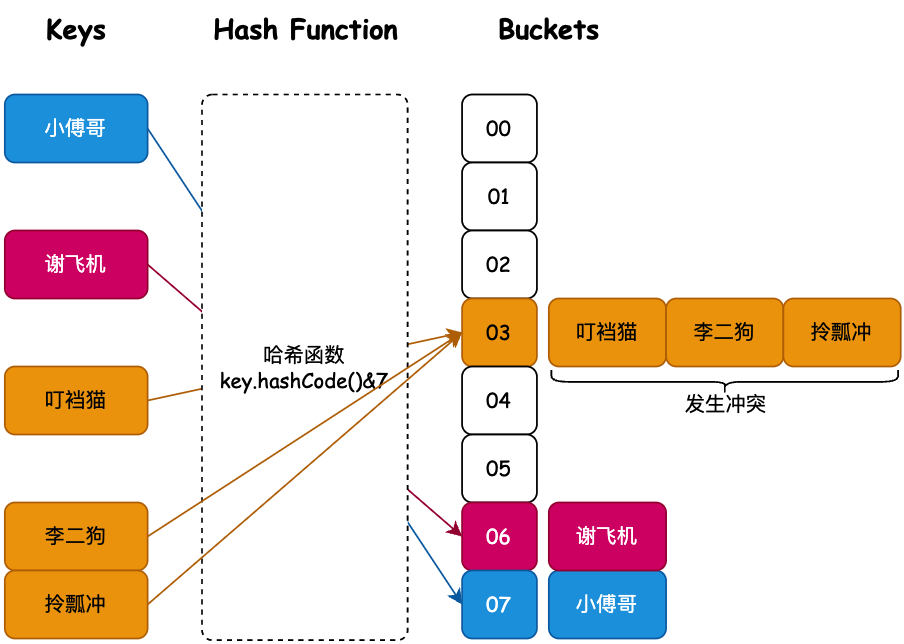
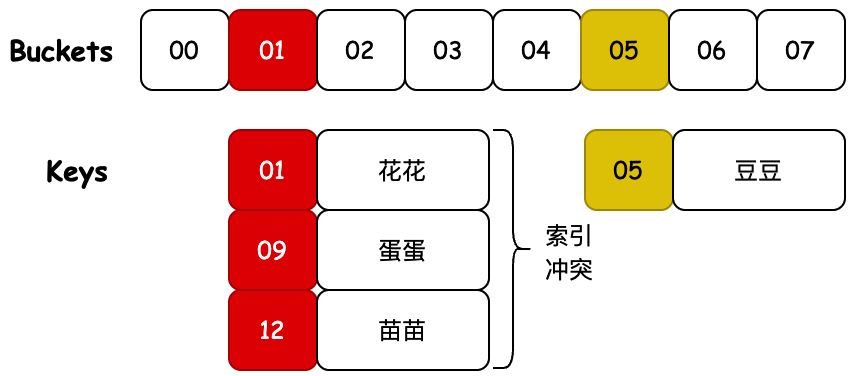
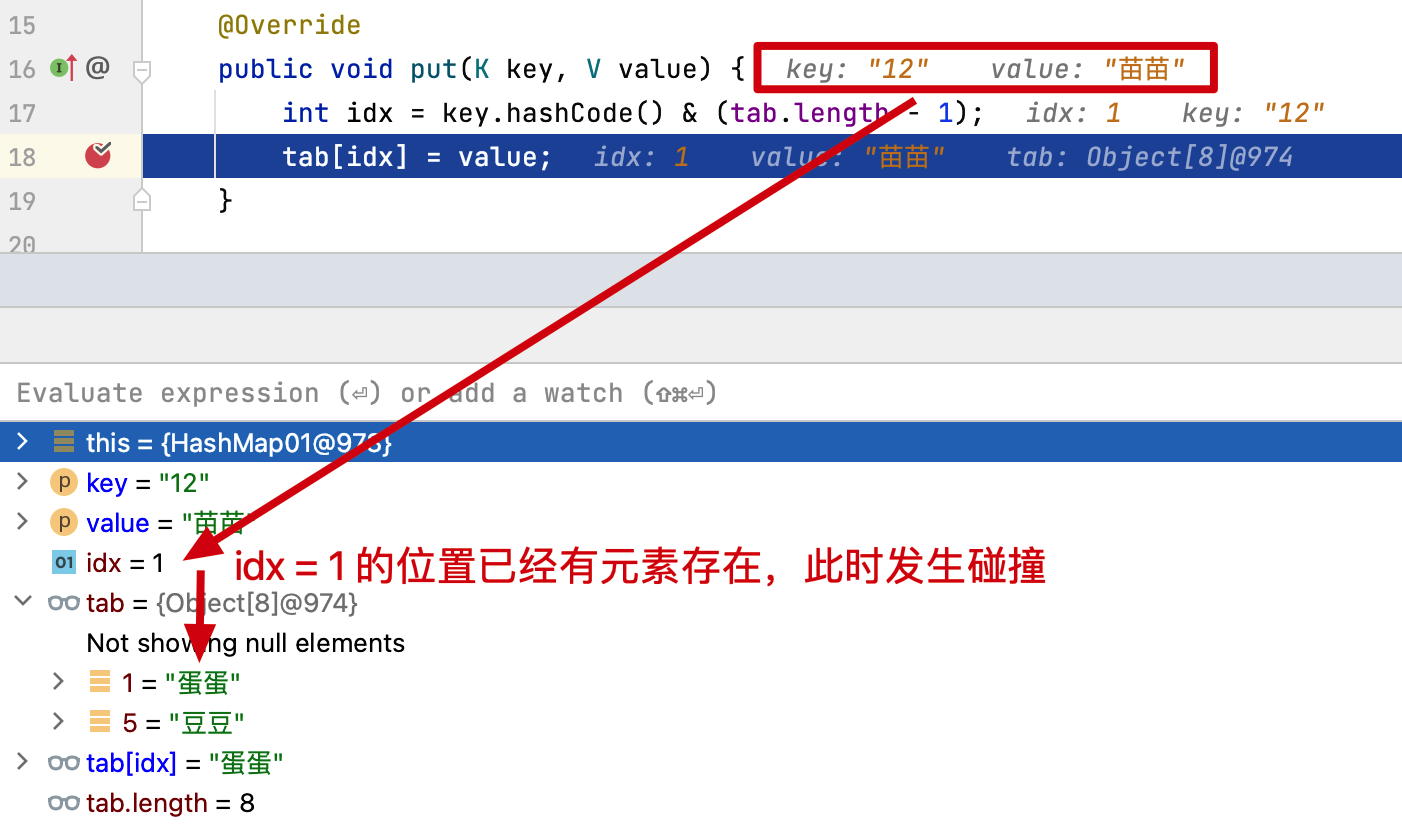
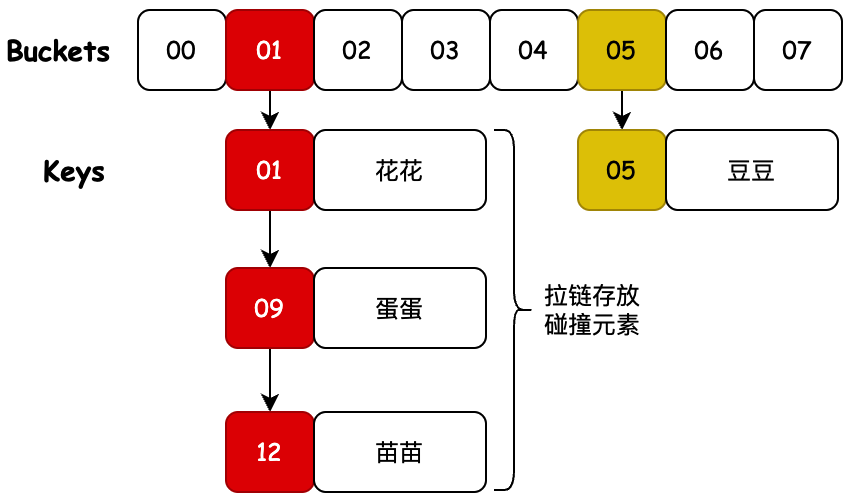
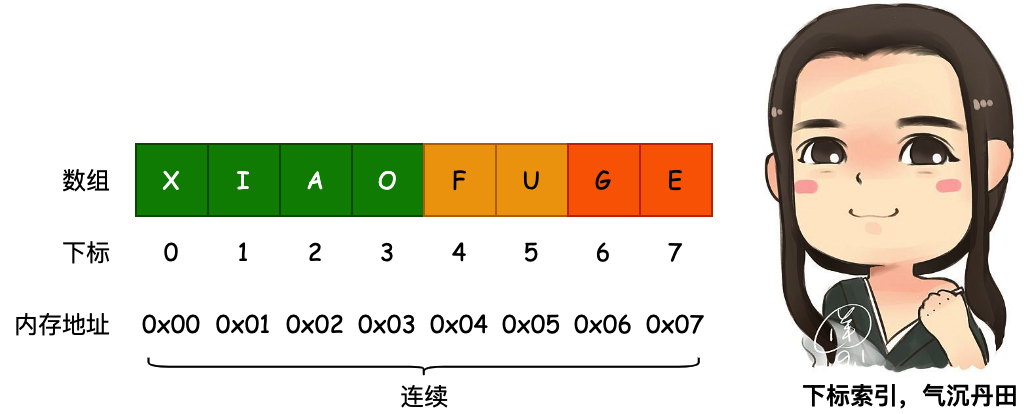
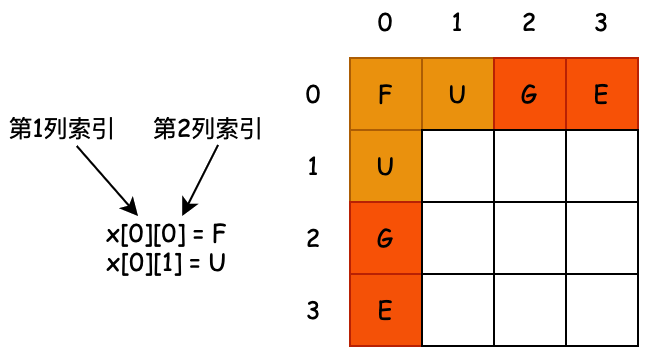
也就是说我们通过对一个 Key 值计算它的哈希并与长度为 2 的 n 次幂的数组减一做与运算,计算出槽位对应的索引,将数据存放到索引下。那么这样就解决了当获取指定数据时,只需要根据存放时计算索引 ID 的方式再计算一次,就可以把槽位上对应的数据获取处理,以此达到时间复杂度为 O (1) 的情况。如图所示;
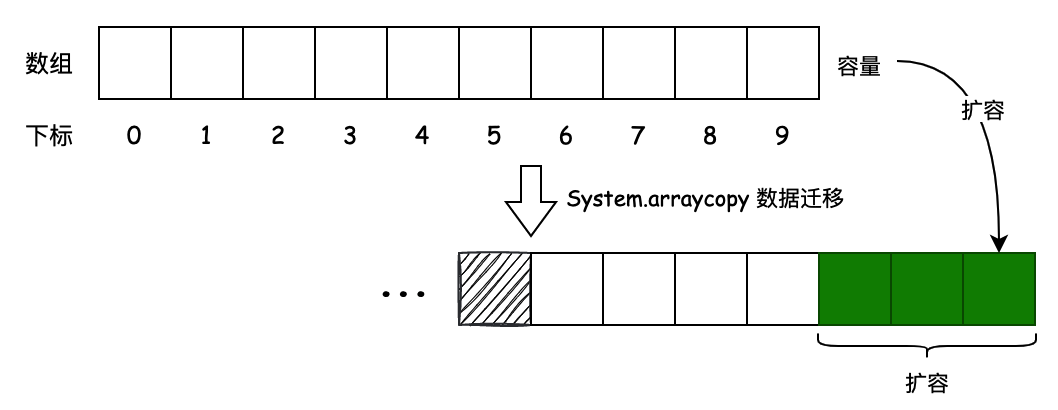
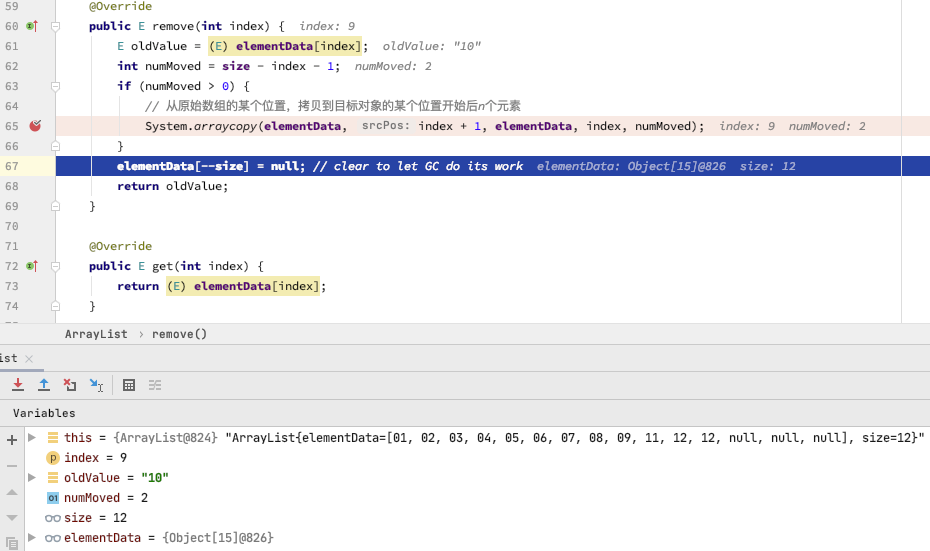
public E remove(int index) { EoldValue= (E) elementData[index]; intnumMoved= size - index - 1; if (numMoved > 0) { // 从原始数组的某个位置,拷贝到目标对象的某个位置开始后n个元素 System.arraycopy(elementData, index + 1, elementData, index, numMoved); } elementData[--size] = null; // clear to let GC do its work return oldValue; }
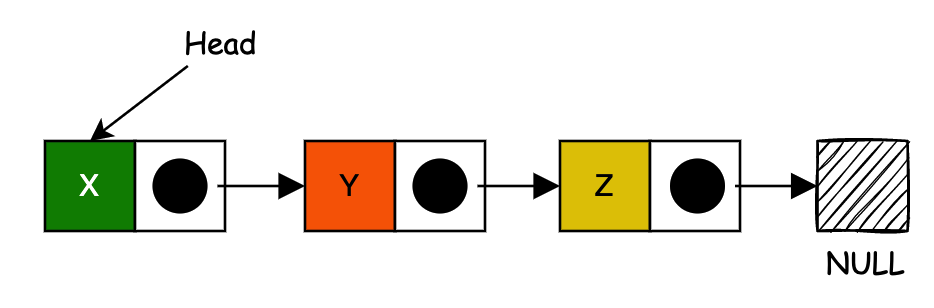
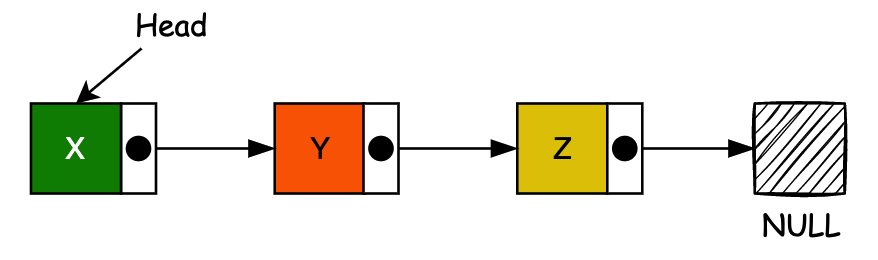
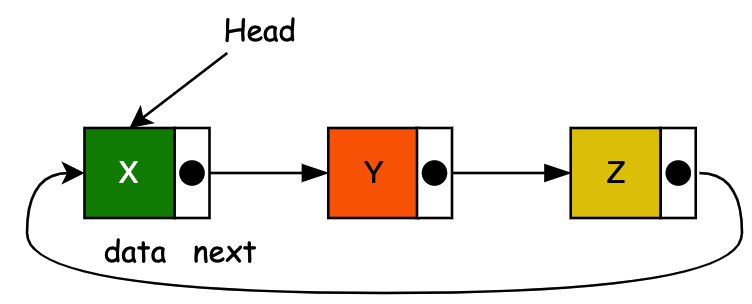
于 1955-1956 年,由兰德公司的 Allen Newell、Cliff Shaw 和 Herbert A. Simon 开发了链表,作为他们的信息处理语言的主要数据结构。链表的另一个早期出现是由 Hans Peter Luhn 在 1953 年 1 月编写的 IBM 内部备忘录建议在链式哈希表中使用链表。
到 1960 年代初,链表和使用这些结构作为主要数据表示的语言的实用性已经很好地建立起来。MIT 林肯实验室的 Bert Green 于 1961 年 3 月在 IRE Transactions on Human Factors in Electronics 上发表了一篇题为 “用于符号操作的计算机语言” 的评论文章,总结了链表方法的优点。1964 年 4 月,Bobrow 和 Raphael 的一篇评论文章 “列表处理计算机语言的比较” 发表在 ACM 通讯中。
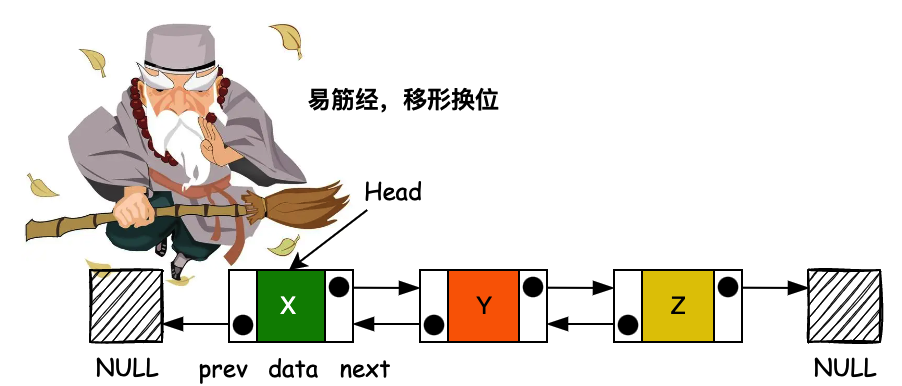
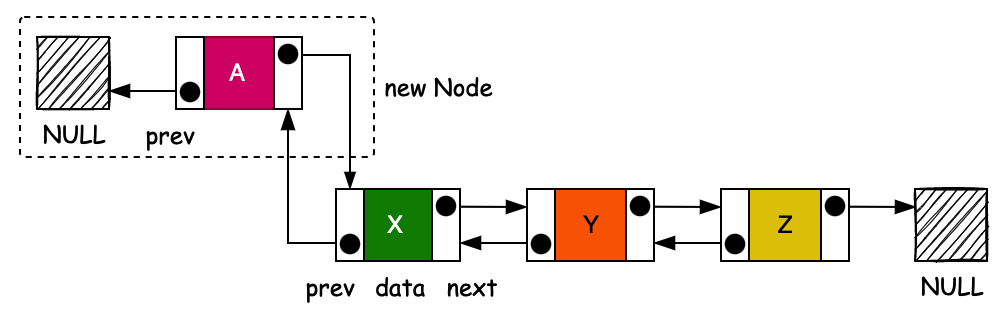
voidlinkFirst(E e) { final Node<E> f = first; final Node<E> newNode = newNode<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; }
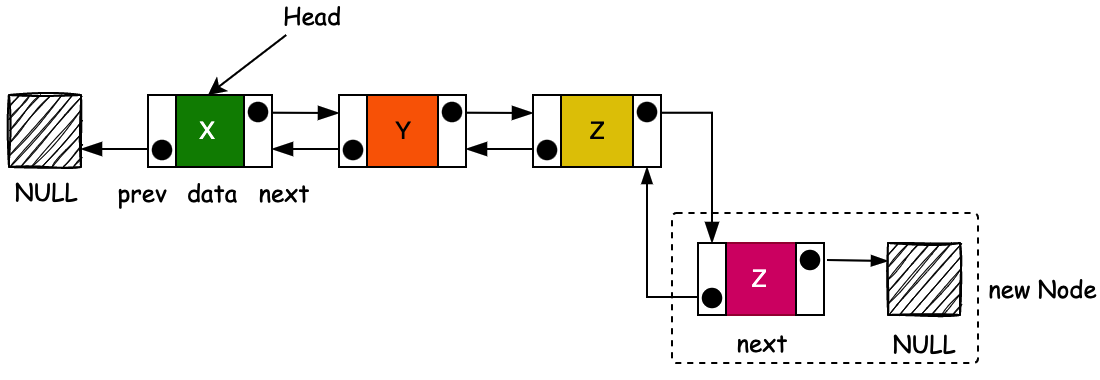
voidlinkLast(E e) { final Node<E> l = last; final Node<E> newNode = newNode<>(l, e, null); last = newNode; if (l == null) { first = newNode; } else { l.next = newNode; } size++; }
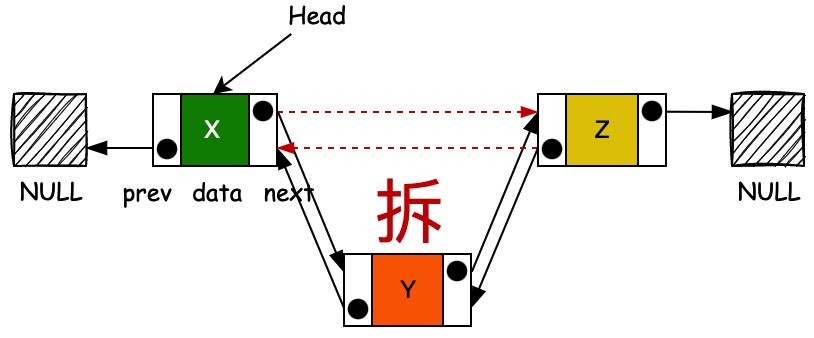
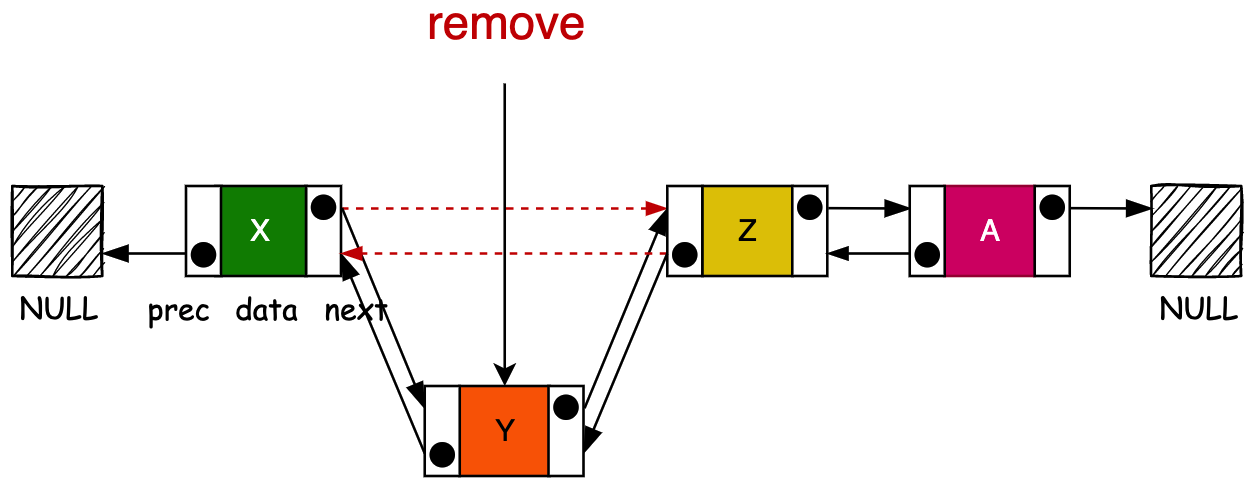
publicbooleanremove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); returntrue; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
删除元素的过程需要 for 循环判断比删除元素的值,找到对应的元素,进行删除。
循环比对的过程是一个 O (n) 的操作,删除的过程是一个 O (1) 的操作。所以如果这个链表较大,删除的元素又都是贴近结尾,那么这个循环比对的过程也是比较耗时的。
因此,另一种更为通用的方法就出来了:「 大 O 符号表示法 」,即 T (n) = O (f (n))
我们先来看个例子:
1 2 3 4 5
for(i=1; i<=n; ++i) { j = i; j++; }
通过「 大 O 符号表示法 」,这段代码的时间复杂度为:O (n) ,为什么呢?
在 大 O 符号表示法中,时间复杂度的公式是: T (n) = O ( f (n) ),其中 f (n) 表示每行代码执行次数之和,而 O 表示正比例关系,这个公式的全称是:算法的渐进时间复杂度。
我们继续看上面的例子,假设每行代码的执行时间都是一样的,我们用 1 颗粒时间 来表示,那么这个例子的第一行耗时是 1 个颗粒时间,第三行的执行时间是 n 个颗粒时间,第四行的执行时间也是 n 个颗粒时间(第二行和第五行是符号,暂时忽略),那么总时间就是 1 颗粒时间 + n 颗粒时间 + n 颗粒时间 ,即 (1+2n) 个颗粒时间,即: T (n) = (1+2n)* 颗粒时间,从这个结果可以看出,这个算法的耗时是随着 n 的变化而变化,因此,我们可以简化的将这个算法的时间复杂度表示为:T (n) = O (n)
为什么可以这么去简化呢,因为大 O 符号表示法并不是用于来真实代表算法的执行时间的,它是用来表示代码执行时间的增长变化趋势的。
所以上面的例子中,如果 n 无限大的时候,T (n) = time (1+2n) 中的常量 1 就没有意义了,倍数 2 也意义不大。因此直接简化为 T (n) = O (n) 就可以了。
常见的时间复杂度量级有:
常数阶 O (1)
对数阶 O (logN)
线性阶 O (n)
线性对数阶 O (nlogN)
平方阶 O (n²)
立方阶 O (n³)
K 次方阶 O (n^k)
指数阶 (2^n)
上面从上至下依次的时间复杂度越来越大,执行的效率越来越低。
下面选取一些较为常用的来讲解一下(没有严格按照顺序):
常数阶 O (1)
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是 O (1),如:
1 2 3 4 5
int i = 1; int j = 2; ++i; j++; int m = i + j;
上述代码在执行的时候,它消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用 O (1) 来表示它的时间复杂度。
线性阶 O (n)
这个在最开始的代码示例中就讲解过了,如:
1 2 3 4 5
for(i=1; i<=n; ++i) { j = i; j++; }
这段代码,for 循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此这类代码都可以用 O (n) 来表示它的时间复杂度。
对数阶 O (logN)
还是先来看代码:
1 2 3 4 5
int i = 1; while(i<n) { i = i * 2; }
从上面代码可以看到,在 while 循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。我们试着求解一下,假设循环 x 次之后,i 就大于 n 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 x = log2^n
也就是说当循环 log2^n 次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(logn)
线性对数阶 O (nlogN)
线性对数阶 O (nlogN) 其实非常容易理解,将时间复杂度为 O (logn) 的代码循环 N 遍的话,那么它的时间复杂度就是 n * O (logN),也就是了 O (nlogN)。
就拿上面的代码加一点修改来举例:
1 2 3 4 5 6 7 8
for(m=1; m<n; m++) { i = 1; while(i<n) { i = i * 2; } }
平方阶 O (n²)
平方阶 O (n²) 就更容易理解了,如果把 O (n) 的代码再嵌套循环一遍,它的时间复杂度就是 O (n²) 了。
举例:
MySQL 主从开关机顺序
停应用 -> 停数据库(先备后主) -> 改配置 -> 启数据库(先主后备)-> 启应用
关闭 MySQL 从库
a. 先查看当前的主从同步状态 show slave statusG; 看是否双 yes
b. 执行 stop slave
c. 停止从库服务 mysqladmin shutdown -u 用户名 -p 密码
d. 查看是否还有 mysql 的进程 ps -ef | grep mysql
d. 如果部署了多个实例,那每个实例都要按照以上步骤来操作
关闭 MySQL 主库
a. 停止主库服务 mysqladmin shutdown -u 用户名 -p 密码
b. 查看是否还有 mysql 的进程 ps -ef | grep mysql
启动 MySQL 主库
a. 启动主库服务 mysqladmin start -u 用户名 -p 密码
b. 查看 mysql 的进程 ps -ef | grep mysql
启动 MySQL 从库
a. 启动从库服务 mysqladmin start -u 用户名 -p 密码
b. 启动复制 start slave;
c. 检查同步状态 show slave statusG; 是否双 yes
d. 查看 mysql 的进程 ps -ef | grep mysql
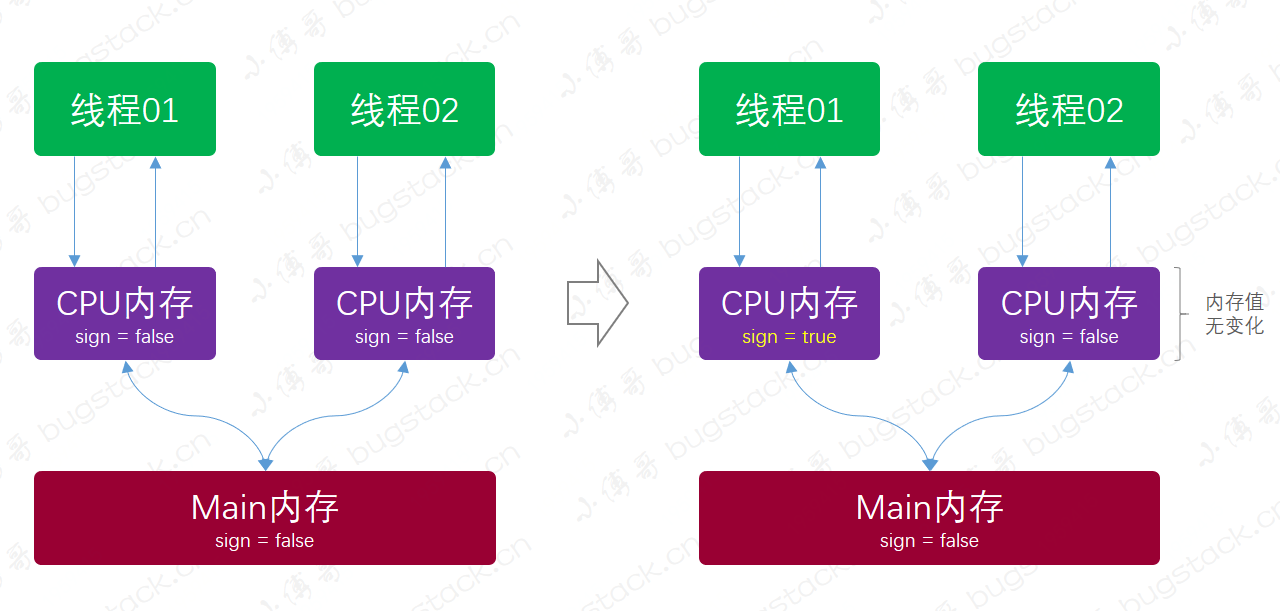
ABA 问题是在多线程并发的情况下,发生的一种现象。上一次记录了有关 CAS 操作的一些知识,CAS 通过比较内存中的一个数据是否是预期值,如果是就将它修改成新值,如果不是则进行自旋,重复比较的操作,直到某一刻内存值等于预期值再进行修改。而 ABA 问题则是在 CAS 操作中存在的一个经典问题,这个问题某些时候不会带来任何影响,某些时候却是影响很大的。
当执行 campare and swap 会出现失败的情况。例如,一个线程先读取共享内存数据值 A,随后因某种原因,线程暂时挂起,同时另一个线程临时将共享内存数据值先改为 B,随后又改回为 A。随后挂起线程恢复,并通过 CAS 比较,最终比较结果将会无变化。这样会通过检查,这就是 ABA 问题。 在 CAS 比较前会读取原始数据,随后进行原子 CAS 操作。这个间隙之间由于并发操作,最终可能会带来问题。