【数据结构】手写实现LinkedList

# 【数据结构】手写实现 LinkedList
# 一、前言
# 链表的历史
于 1955-1956 年,由兰德公司的 Allen Newell、Cliff Shaw 和 Herbert A. Simon 开发了链表,作为他们的信息处理语言的主要数据结构。链表的另一个早期出现是由 Hans Peter Luhn 在 1953 年 1 月编写的 IBM 内部备忘录建议在链式哈希表中使用链表。
到 1960 年代初,链表和使用这些结构作为主要数据表示的语言的实用性已经很好地建立起来。MIT 林肯实验室的 Bert Green 于 1961 年 3 月在 IRE Transactions on Human Factors in Electronics 上发表了一篇题为 “用于符号操作的计算机语言” 的评论文章,总结了链表方法的优点。1964 年 4 月,Bobrow 和 Raphael 的一篇评论文章 “列表处理计算机语言的比较” 发表在 ACM 通讯中。
# 二、链表数据结构
在计算机科学中,链表是数据元素的线性集合,元素的线性顺序不是由它们在内存中的物理地址给出的。它是由一组节点组成的数据结构,每个元素指向下一个元素,这些节点一起,表示线性序列。
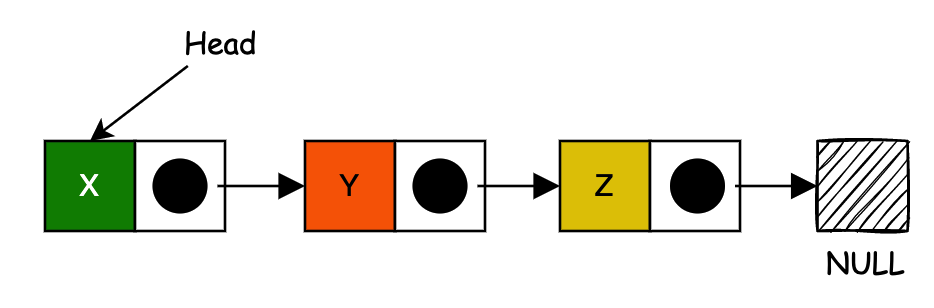
在最简单的链表结构下,每个节点由数据和指针(存放指向下一个节点的指针)两部分组成,这种数据结构允许在迭代时有效地从序列中的任何位置插入或删除元素。
链表的数据结构通过链的连接方式,提供了可以不需要扩容空间就更高效的插入和删除元素的操作,在适合的场景下它是一种非常方便的数据结构。但在一些需要遍历、指定位置操作、或者访问任意元素下,是需要循环遍历的,这将导致时间复杂度的提升。
# 三、链表分类类型
链表的主要表现形式分为;单向链表、双向链表、循环链表,接下来我们分别介绍下。
# 1. 单向链表
单链表包含具有数据字段的节点以及指向节点行中的下一个节点的 “下一个” 字段。可以对单链表执行的操作包括插入、删除和遍历。
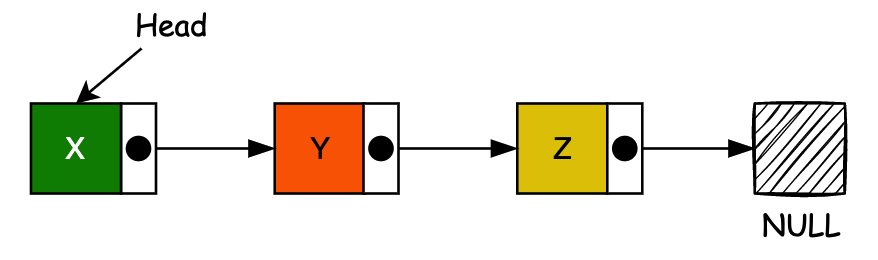
# 2. 双向链表
在 “双向链表” 中,除了下一个节点链接之外,每个节点还包含指向序列中 “前一个” 节点的第二个链接字段。这两个链接可以称为’forward(‘s’)和’backwards’,或’next’和’prev’(‘previous’)。
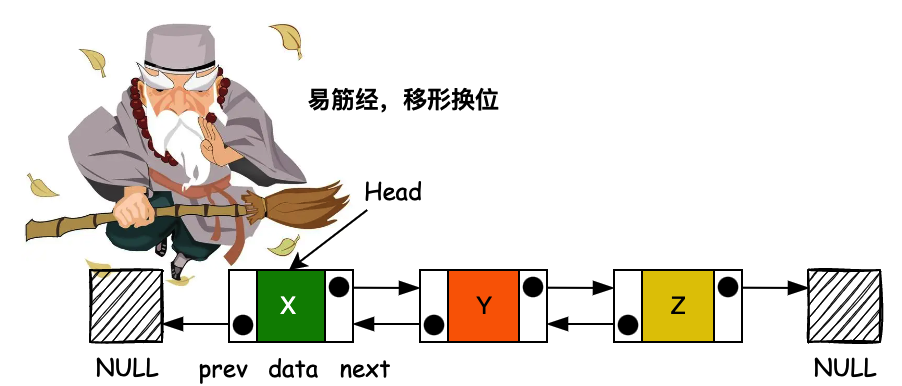
# 3. 循环链表
在列表的最后一个节点中,链接字段通常包含一个空引用,一个特殊的值用于指示缺少进一步的节点。一个不太常见的约定是让它指向列表的第一个节点。在这种情况下,列表被称为 “循环” 或 “循环链接”;否则,它被称为 “开放” 或 “线性”。它是一个列表,其中最后一个指针指向第一个节点。
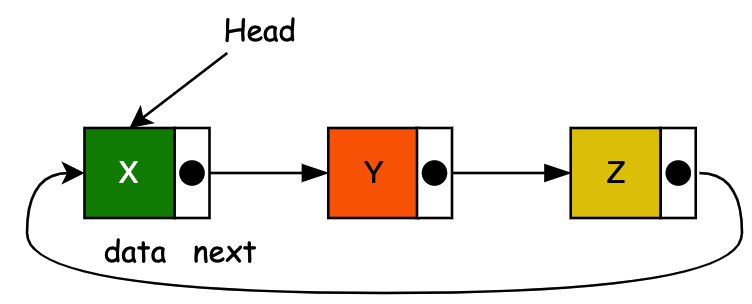
# 四、实现一个链表
# 1. 链表节点
1 | private static class Node<E> { |
- 链表的数据结构核心根基就在于节点对象的使用,并在节点对象中关联当前节点的上一个和下一个节点。通过这样的方式构建出链表结构。
- 但也因为在链表上添加每个元素的时候,都需要创建新的 Node 节点,所以这也是一部分耗时的操作。
# 2. 头插节点
1 | void linkFirst(E e) { |
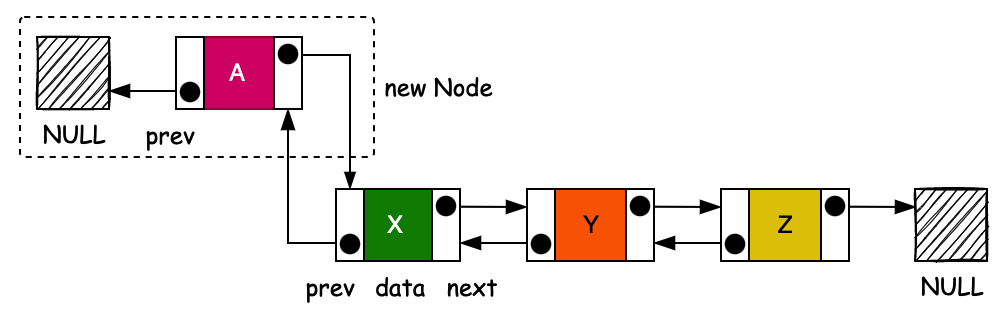
- 头插的操作流程,先把头节点记录下来。之后创建一个新的节点,新的节点构造函数的头节点入参为 null,通过这样的方式构建出一个新的头节点。
- 原来的头结点,设置 f.prev 连接到新的头节点,这样的就可以完成头插的操作了。另外如果原来就没有头节点,头节点设置为新的节点即可。最后记录当前链表中节点的数量,也就是你使用 LinkedList 获取 size 时候就是从这个值获取的。
# 3. 尾插节点
1 | void linkLast(E e) { |
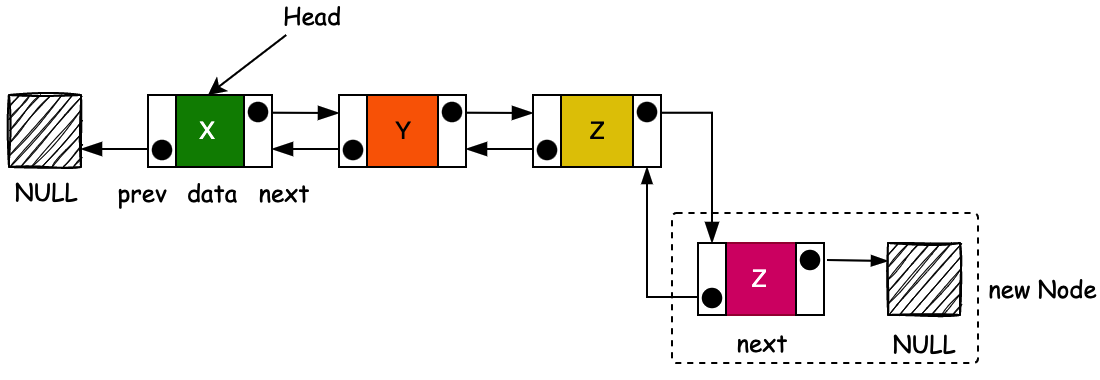
- 尾差节点与头插节点正好相反,通过记录当前的结尾节点,创建新的节点,并把当前的结尾节点,通过 l.next 关联到新创建的节点上。同时记录 size 节点数量值。
# 4. 拆链操作
1 | E unlink(Node<E> x) { |
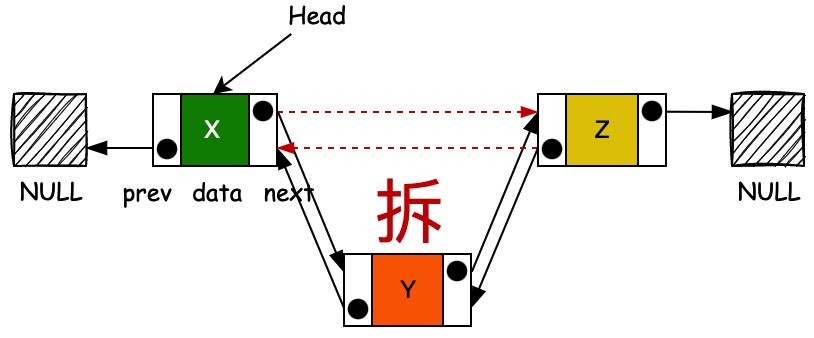
- unlink 是一种拆链操作,只要你给定一个元素,它就可以把当前这个元素的上一个节点和一个节点进行相连,之后把自己拆除。
- 这个方法常用于 remove 移除元素操作,因为整个操作过程不需要遍历,拆除元素后也不需要复制新的空间,所以时间复杂读为 O (1)
# 5. 删除节点
1 | public boolean remove(Object o) { |
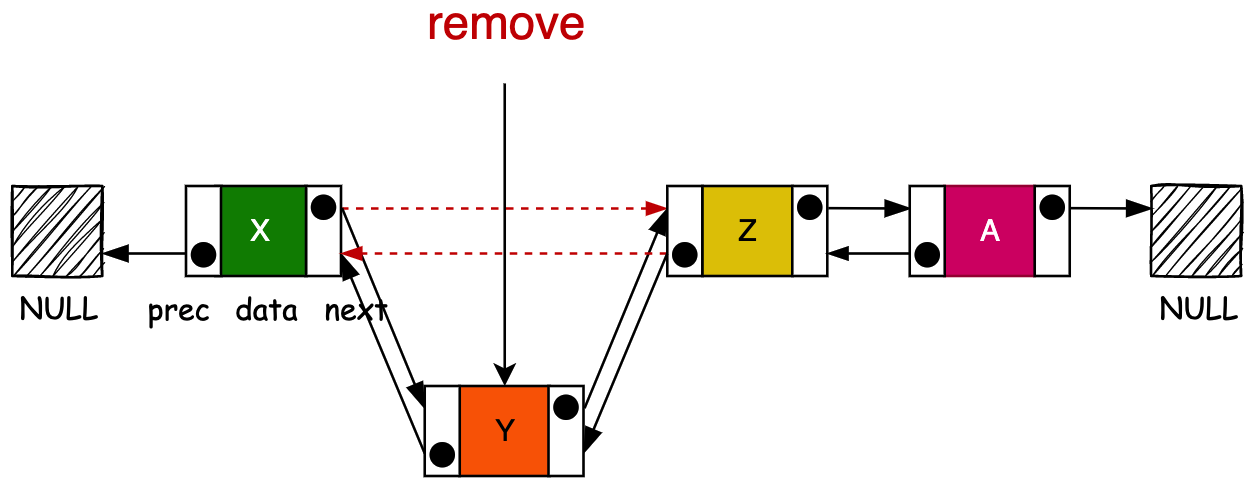
- 删除元素的过程需要 for 循环判断比删除元素的值,找到对应的元素,进行删除。
- 循环比对的过程是一个 O (n) 的操作,删除的过程是一个 O (1) 的操作。所以如果这个链表较大,删除的元素又都是贴近结尾,那么这个循环比对的过程也是比较耗时的。
# 五、链表使用测试
1 | public static void main(String[] args) { |
测试结果
1 | 目前的列表,头节点:b 尾节点:c 整体:b,a,c, |
- 按照我们的测试链表对数据的操作过程,从测试结果可以看到,已经满足了链表数据结构的使用。
# 六、常见面试问题
-
描述一下链表的数据结构?
1
2答:
链表是一种常见的数据结构,用于按顺序存储和访问元素集合。它由多个节点组成,每个节点包含两个部分:数据和指向下一个节点的指针。 -
Java 中 LinkedList 使用的是单向链表、双向链表还是循环链表?
1
2答:
Java 中的 LinkedList 使用的是双向链表,每个节点都有一个指向前置节点和后继节点的指针。这使得在 LinkedList 中进行插入和删除操作的效率比 ArrayList 更高。 -
链表中数据的插入、删除、获取元素,时间复杂度是多少?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16答:
插入元素(O(n)):
在链表中插入一个元素通常需要执行以下操作:
在待插入位置之前查找元素O(n)
将新元素插入到该位置O(1)
因此,插入元素的时间复杂度是O(n)。
删除元素(O(n)):
在链表中删除一个元素通常需要执行以下操作:
在待删除位置之前查找元素O(n)
删除该位置上的元素O(1)
因此,删除元素的时间复杂度也是O(n)。
获取元素(O(n)):
在链表中获取一个元素通常需要遍历整个链表,直到找到目标元素。
因此,获取元素的时间复杂度也是O(n)。 -
什么场景下使用链表更合适?
1
2
3
4答:
1.频繁的进行插入和删除操作
2.不需要随机访问元素
3.单纯的遍历操作
# 关于我
Brath 是一个热爱技术的 Java 程序猿,公众号「InterviewCoder」定期分享有趣有料的精品原创文章!

非常感谢各位人才能看到这里,原创不易,文章如果有帮助可以关注、点赞、分享或评论,这都是对我的莫大支持!

